Reduce LLM Serving Costs by up to 65%
Accelerate AI deployment and inference while optimizing hardware infrastructure
Try NowCompanies that trust us

Slash LLM deployment time from weeks to minutes
Preview performance, right-size resources and automatically apply optimizations in a single click with CentML
Peak Performance, Maximum Flexibility
Deploy on any cloud or VPC. Abstract away configuration complexity. Get the latest hardware at the best pricing without contract lock-in.





Our solution
Take the guesswork out of LLM deployment.
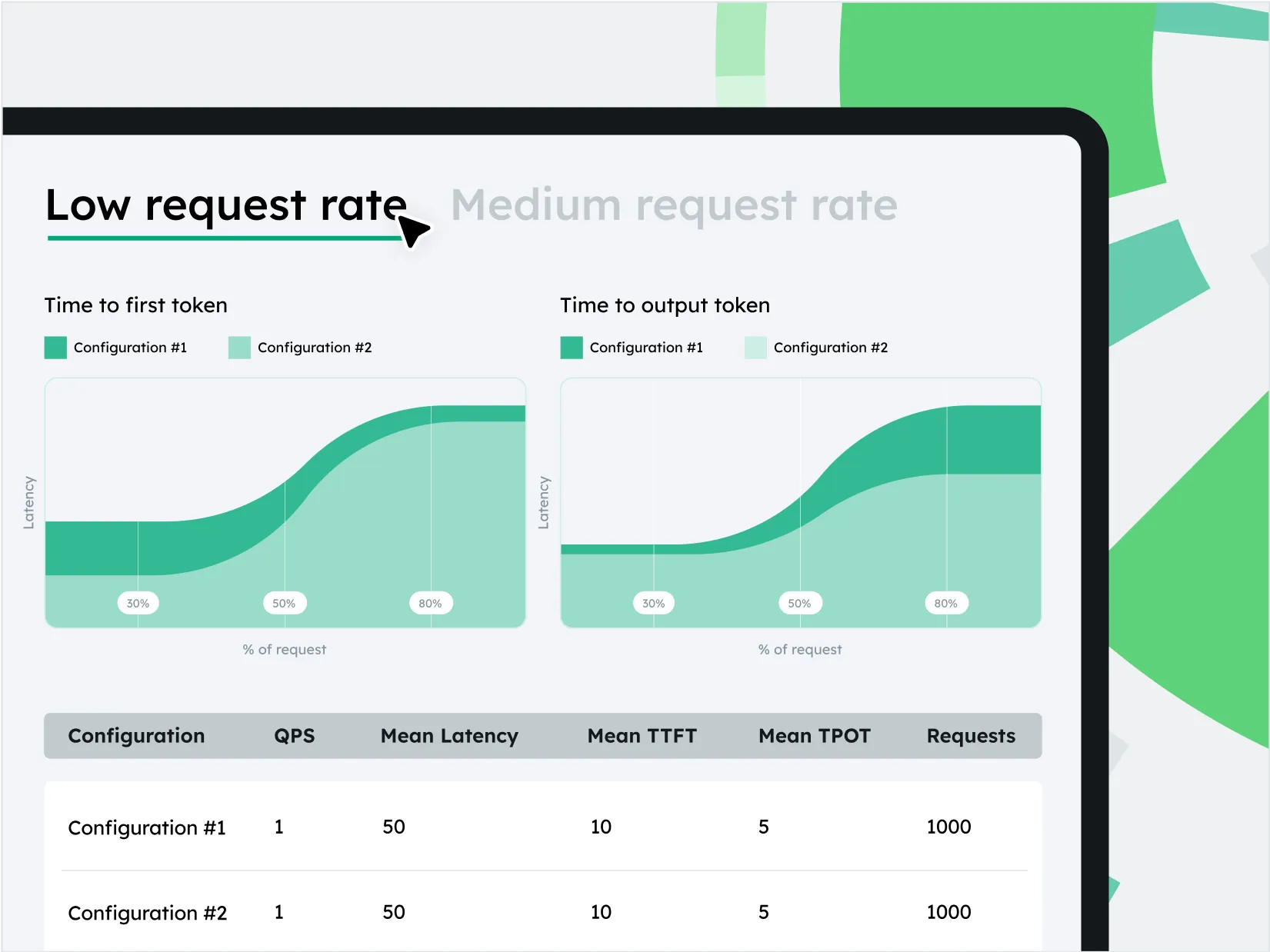
Advanced System Optimization
Save costs with more efficient hardware utilization.
Right-size hardware usage with cutting-edge memory management techniques.
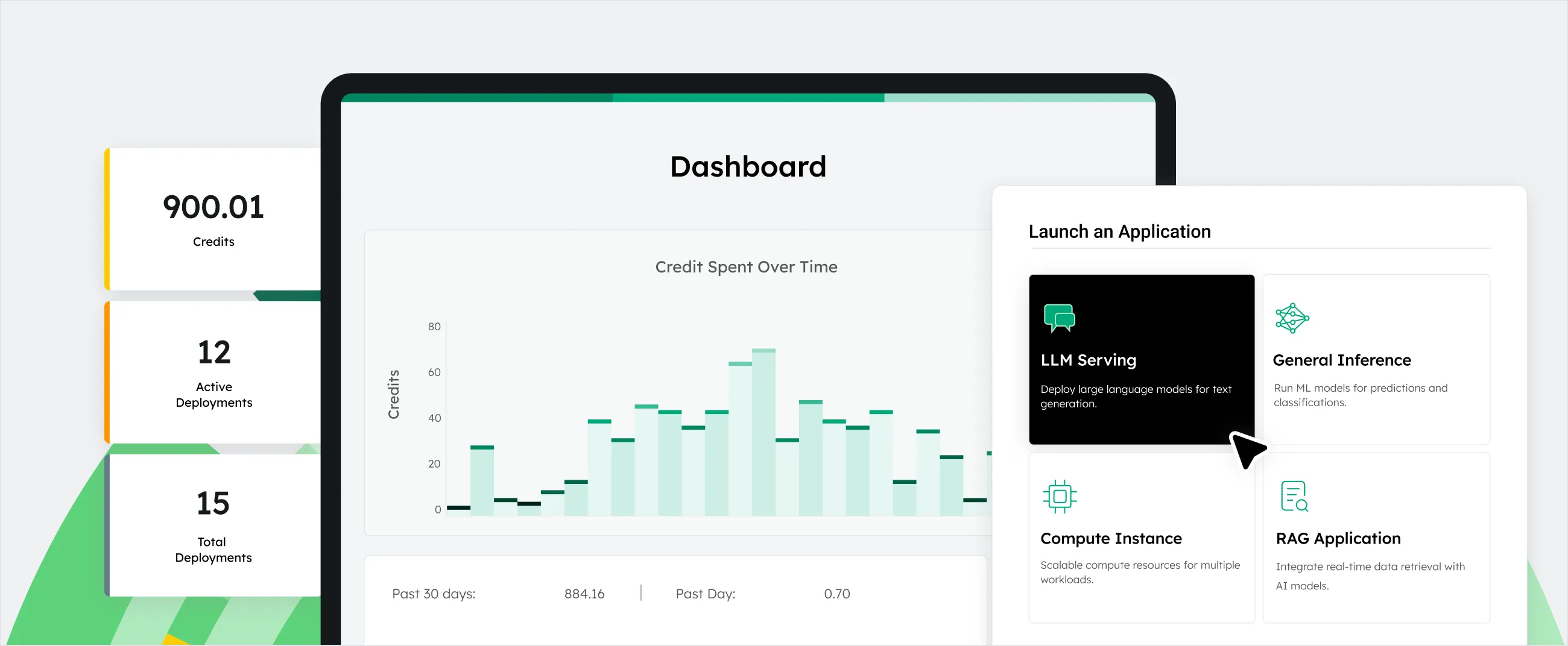
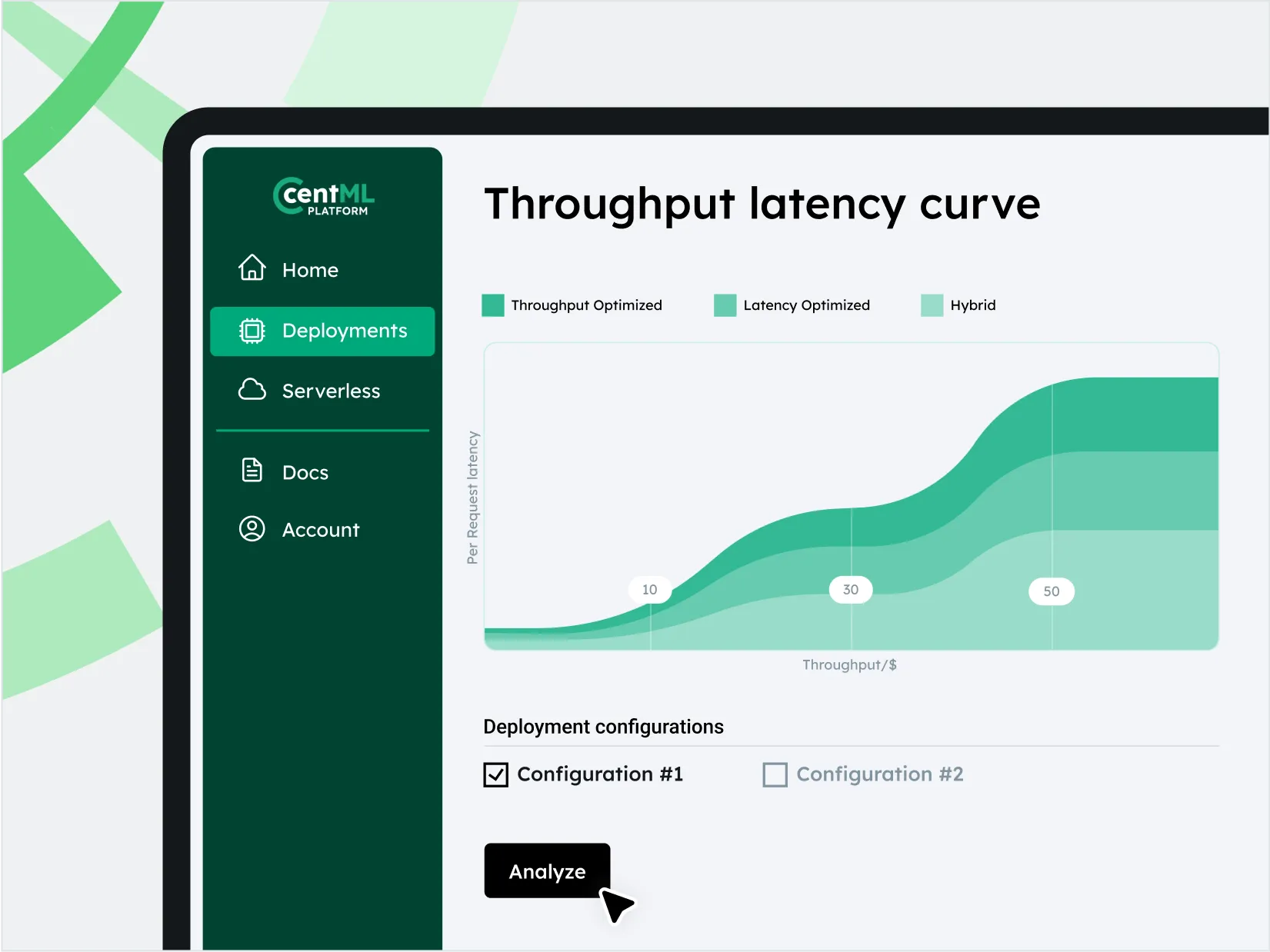
Deployment Planning and Serving at Scale
Streamline LLM deployment with single-click resource sizing and model serving.
Boost performance with reduced latency and maximized throughput at scale.
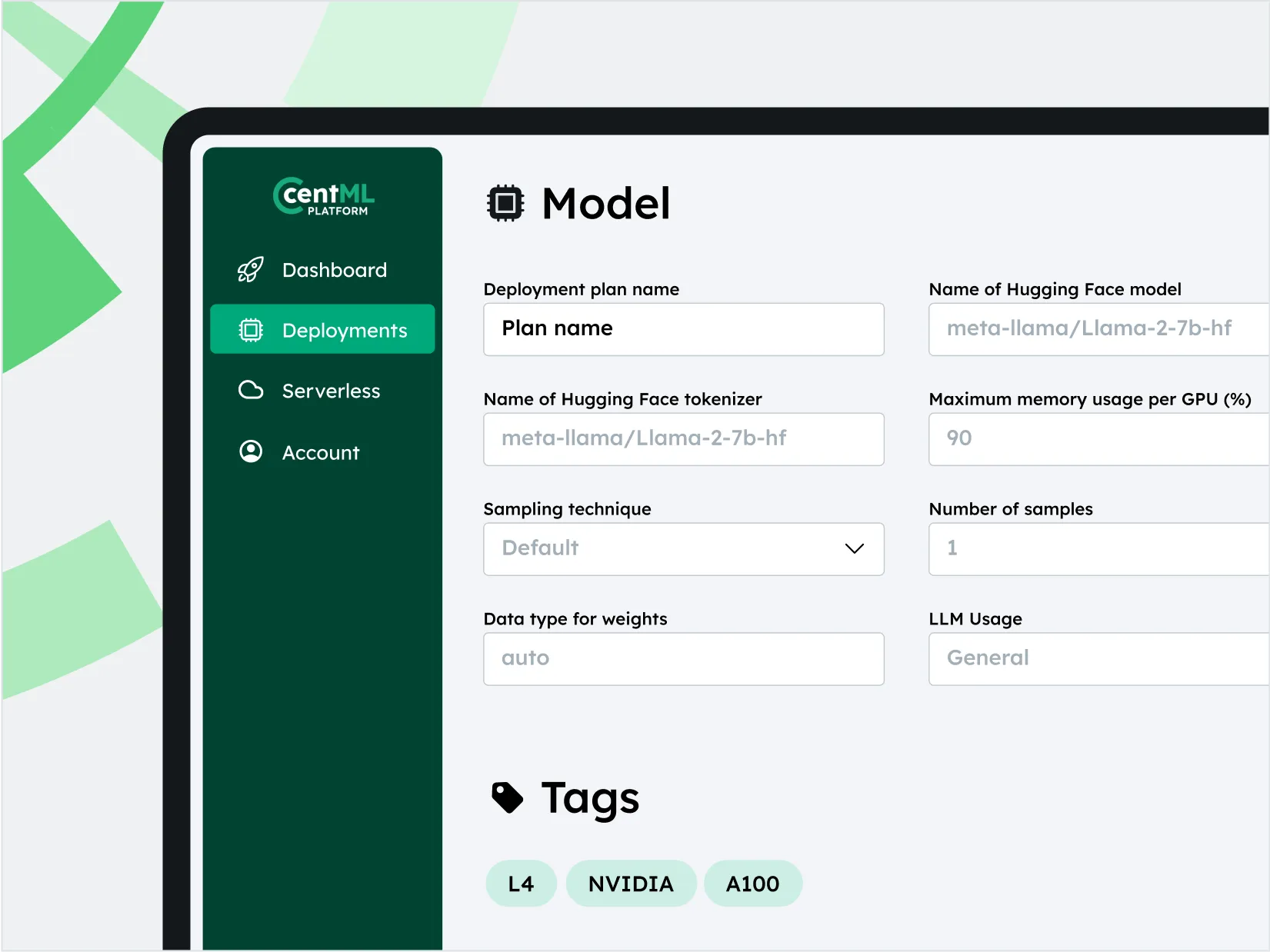
Diverse Hardware, Model, and Modality Support
Day 1 support for popular open source LLMs to unlock your agentic use cases.
Enterprise-grade execution engine supports multiple backends and compute.
Case Studies
-
Maximizing LLM training and inference efficiency using CentML on OCI
In partnership with CentML, Oracle has developed innovative solutions to meet the growing demand for high-performance NVIDIA GPUs for machine learning (ML) model training and inference.
Maximizing LLM training and inference efficiency using CentML on OCI
- 48%
- improvement on LLaMA inference serving performance
- 1.2x
- increase in performance on NVIDIA A100
-
GenAI company cuts training costs by 36% with CentML
A growing generative AI company partnered with CentML to accelerate their API-as-a-service and iterate with foundational models.
GenAI company cuts training costs by 36% with CentML
- 36%
- lower training costs
- 56%
- increase in performance on NVIDIA A100


Ecosystem Support
Testimonials
Technologies you are developing will revolutionize Deep Learning optimization and capacity availability.

Misha Bilenko
VP of AI @ Microsoft Azure
Software is King. Architecture without a good compiler is like a race car without a good driver. I'm excited to be advising a company that is helping push the state-of-the-art in ML as well as help with reductions in carbon emissions.

David Patterson
Distinguished Engineer @ Google
With the breakneck pace of generative AI, we're always looking for an edge to stay ahead of the competition. One main focus is optimizing our API-as-a-Service for speed and efficiency, to provide the best experience for our customers. CentML assisted Wordcab with a highly personalized approach to optimizing our inference servers. They were patient, attentive, and transparent, and worked with us tirelessly to achieve inference speedups of 1.5x to 2x.

Aleks Smechov
CEO & Co-founder @ Wordcab
The most innovative Deep Learning is usually coded as a sequence of calls to large general purpose libraries. Until recently we had little or no sophisticated compiler technology that could transform and optimize such code, so the world depended on library maintainers to manually tune for each important DL paradigm and use case. Recently compilers have begun to arrive. Some are too low level and others are too specialized to high level paradigms. CentML's compiler tech is just right -- powerful, flexible, and impactful for training and inference optimization.

Garth Gibson
Former CEO & President @ Vector Institute
I'm excited to be advising a company that is helping push the state-of-the-art in ML as well as help with reductions in carbon emissions.
David Patterson
Distinguished Engineer @ Google
Amazing team, conducting cutting edge work that will revolutionize the way we are training and deploying large-scale deep learning systems.

Ruslan Salakhutdinov
CMU Professor
With CentML's expertise, and seamless integration of their ML monitoring tools, we have been able to optimize our research workflows to achieve greater efficiency, thereby reducing compute costs and accelerating the pace of our research.

Graham Taylor
Vector Institute for Artificial Intelligence
The proliferation of generative AI is creating a new base of developers, researchers, and scientists seeking to use accelerated computing for a host of capabilities. CentML's work to optimize AI and ML models on GPUs in the most efficient way possible is helping to create a faster, easier experience for these individuals.

Vinod Grover
Senior Distinguished Engineer and Director of CUDA and Compiler Software at NVIDIA
CentML's compiler technology is proven to deliver impressive training and inference optimizations. We anticipate these solutions will bring significant benefits for our ML model development efforts, helping us best serve our customers.

Tamara Steffens
TR Ventures Managing Director
Get started with CentML
Ready to simplify your LLM deployment and accelerate your AI initiatives? Let's talk.
Book a Demo