Reduce LLM Serving Costs by up to 65%
Elevate your AI efficiency to accelerate deployment and inference while optimizing GPU infrastructure
Book a DemoCompanies that trust us












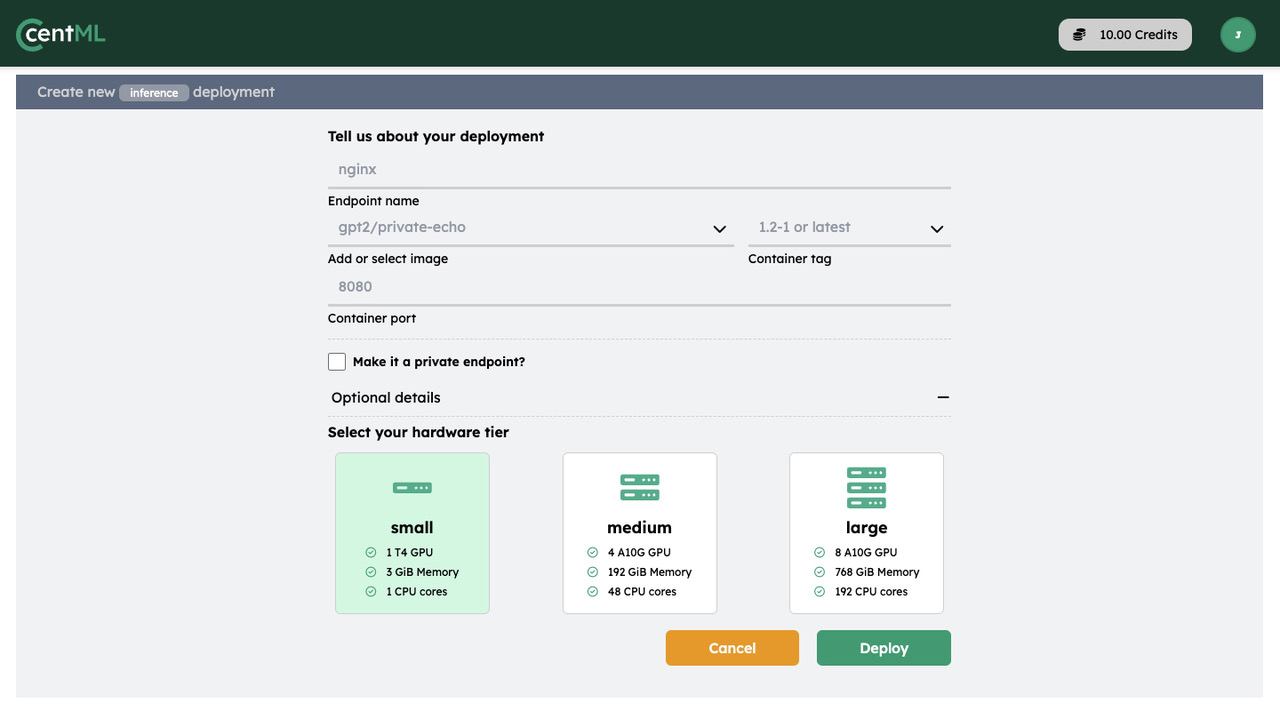
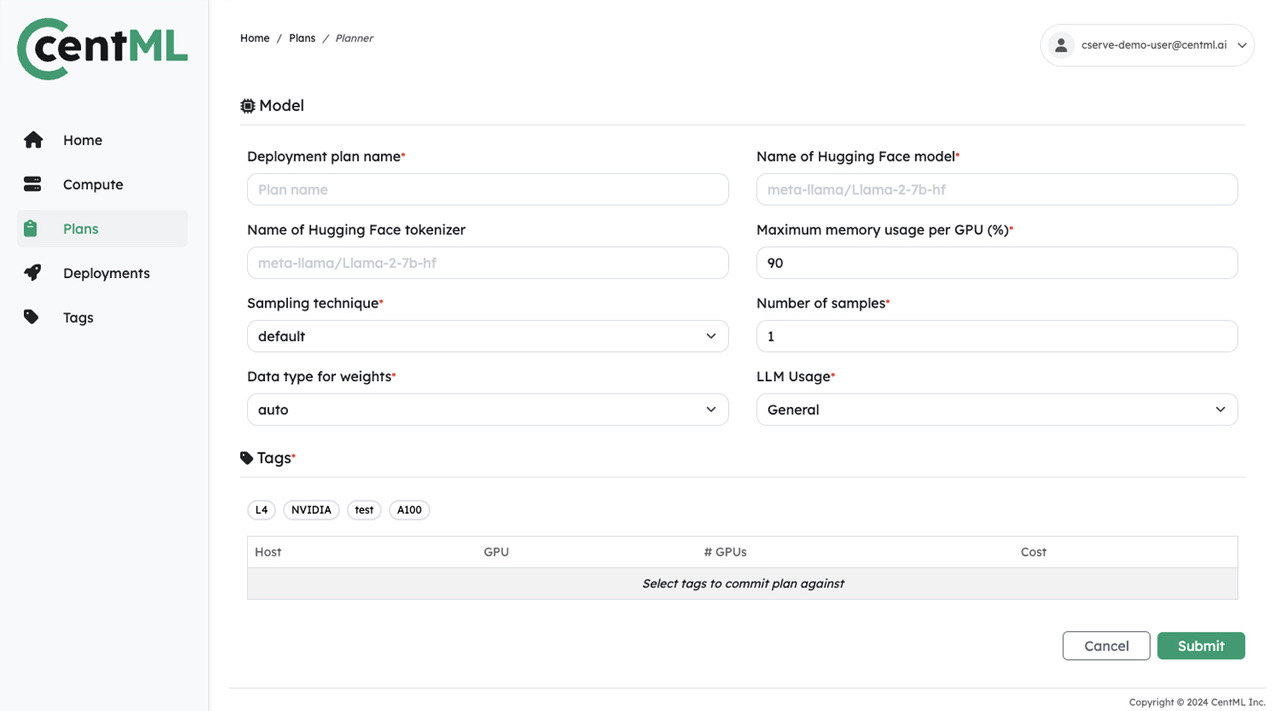
Slash LLM Deployment Time from weeks to minutes
Preview Performance, right-size resources and automatically apply all LLM optimizations in a single click with CentML Planner
Peak performance on all generation of GPUs
Optimize model performance on a range of deployment options, including non-flagship hardware, as suitable to your needs.





Our Solutions
LLM Serving with automated compute optimizations
Advanced Memory Optimization
Fit larger models on affordable GPUs with our cutting-edge memory management techniques.
Enable efficient utilization of GPU resources to save costs.
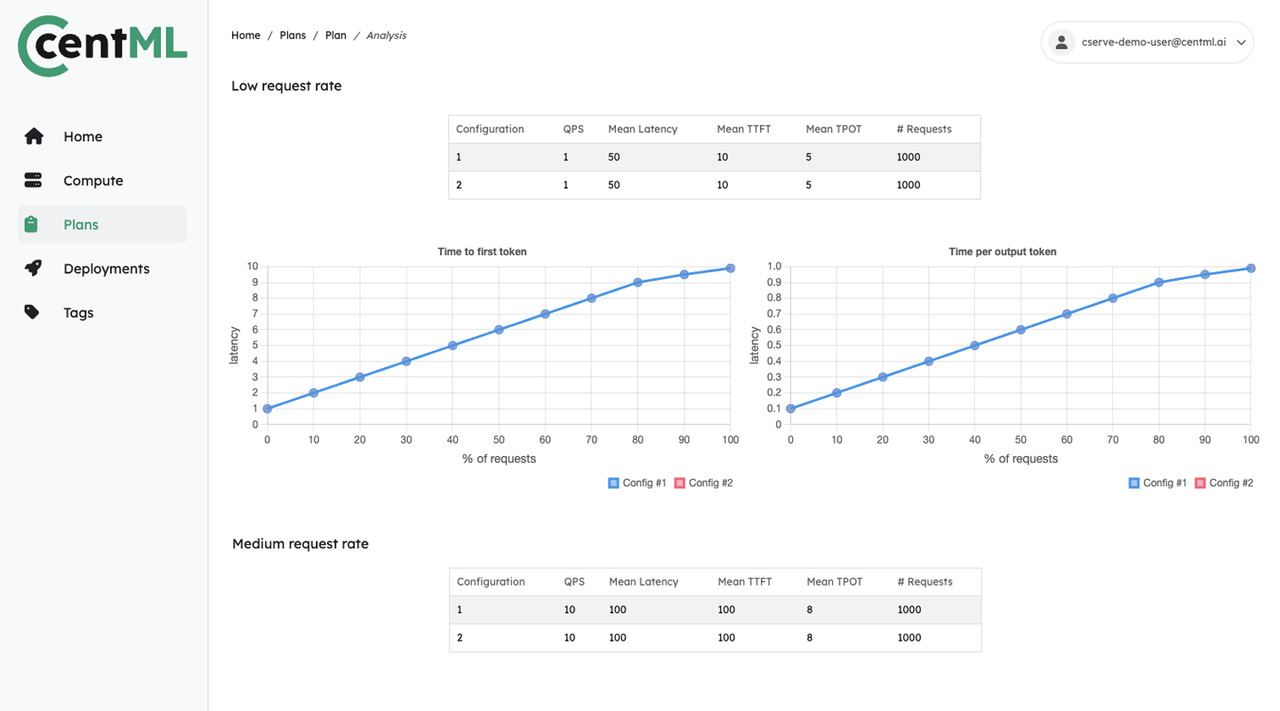
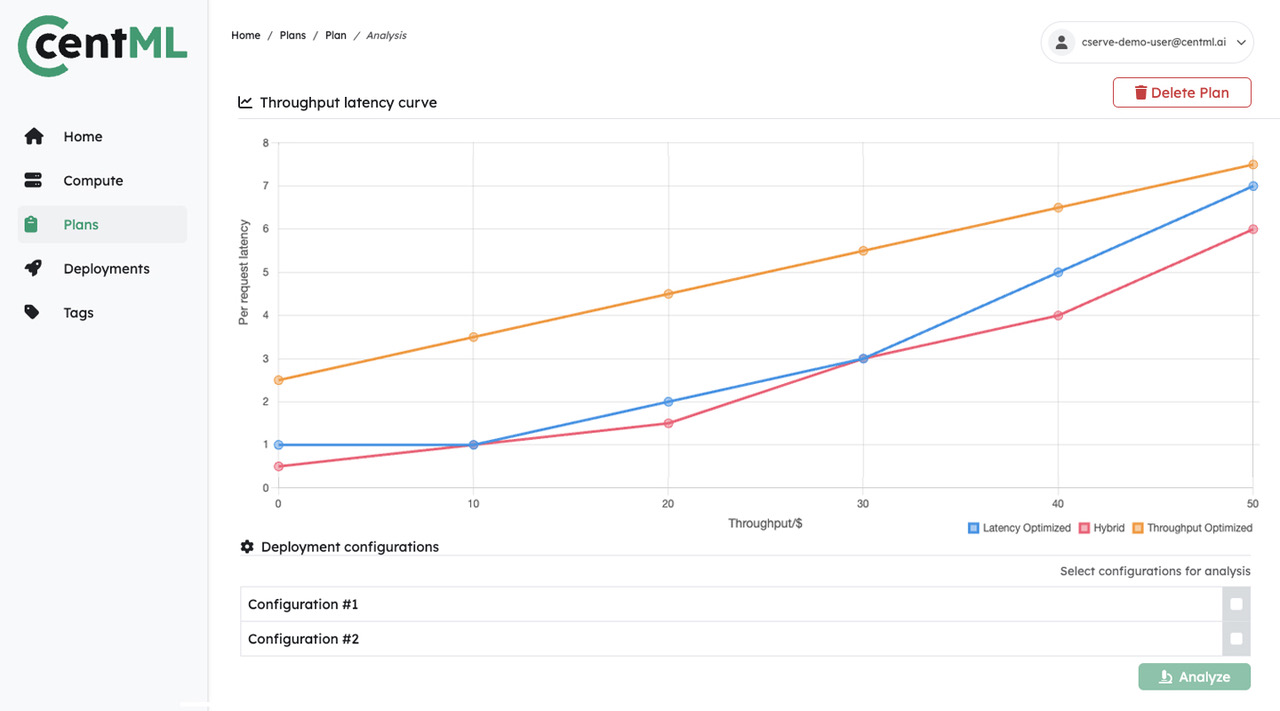
Deployment Planning and Serving
Streamline your LLM deployment with single-click resource sizing and model serving
Ensure high performance with reduced latency and maximized throughput at scale.
Customized Model Training
Fine-tune your models for specific applications with optimized training workflows.
Achieve faster training times and higher throughput on existing hardware.
Case Studies
Examples of some of the solutions we have developed for our clients
Maximizing LLM training and inference efficiency using CentML on OCI
In partnership with CentML, Oracle has developed innovative solutions to meet the growing demand for high-performance NVIDIA GPUs for machine learning (ML) model training and inference.

48%
improvement on LLaMA inference serving performance
1.2x
increase in performance on NVIDIA A100
GenAI company cuts training costs by 36% with CentML
A growing generative AI company partnered with CentML to accelerate their API-as-a-service and iterate with foundational models.

36%
lower training costs
56%
throughput improvement
Introducing CServe: Reduce LLM deployment cost by more than 50%
Run LLMs on budget-friendly GPUs and still get top-notch results.

58%
reduction in LLM deployment costs
43%
reduction while maintaining client-side latency constraints
Technological Integrations
Testimonials

Misha Bilenko
VP of AI @ Microsoft Azure

David Patterson
Distinguished Engineer @ Google

Aleks Smechov
CEO & Co-founder @ Wordcab

Garth Gibson
Former CEO & President @ Vector Institute
David Patterson
Distinguished Engineer @ Google

Ruslan Salakhutdinov
CMU Professor

Graham Taylor
Vector Institute for Artificial Intelligence

Vinod Grover
Senior Distinguished Engineer and Director of CUDA and Compiler Software at NVIDIA

Tamara Steffens
TR Ventures Managing Director
Media About Us






