
New user? Try us for free! Get 2M tokens on Llama 4.
AI Made Easy
The CentML Platform is a secure, full stack solution for AI development and deployment.
Try Now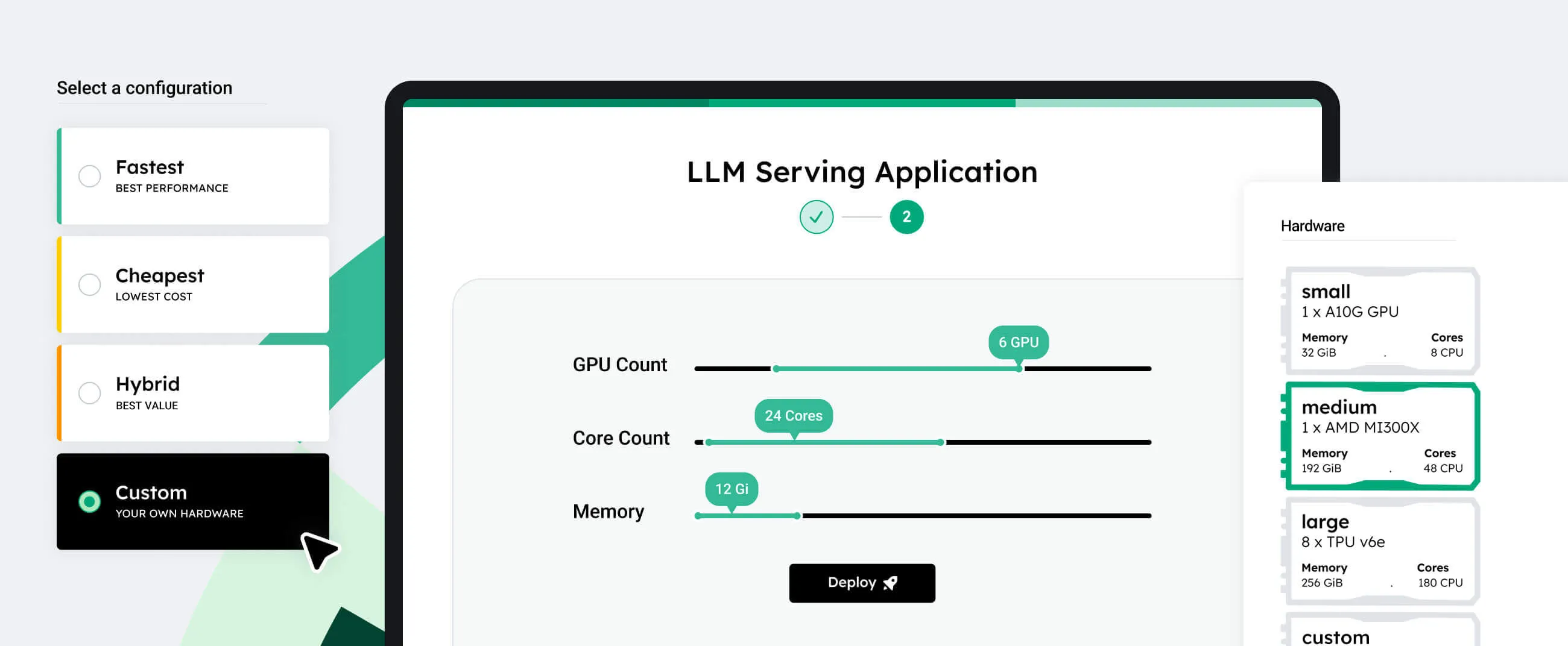
Best performance, price, efficiency. No compromises!
CentML Platform delivers top-tier performance with flexible and competitive pricing. Choose between per-minute or per-token billing, making deployment efficient and cost-effective.
5X
faster than Bedrock

12X
lower cost than ChatGPT4

2.5X
more efficient than vLLM
Model: Llama-3.1-405B-Instruct-FP8. Average Speed: The best case request speed (in output tokens) obtained from the serverless endpoint, across tasks like Q/A, story generation, coding, math, science and finance.
Unlock the Power of Gen AI
Integrated Platform for AI/ML Development and Deployment
CentML offers an end-to-end solution for all your AI needs
- Serverless APIs
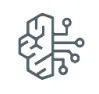
- Securely experiment with popular open-source LLMs in a chatbot interface.
- Fine-Tuning (Coming Soon)
- Use your own data to customize pre-trained models for your specific applications with complete security.
- Inference
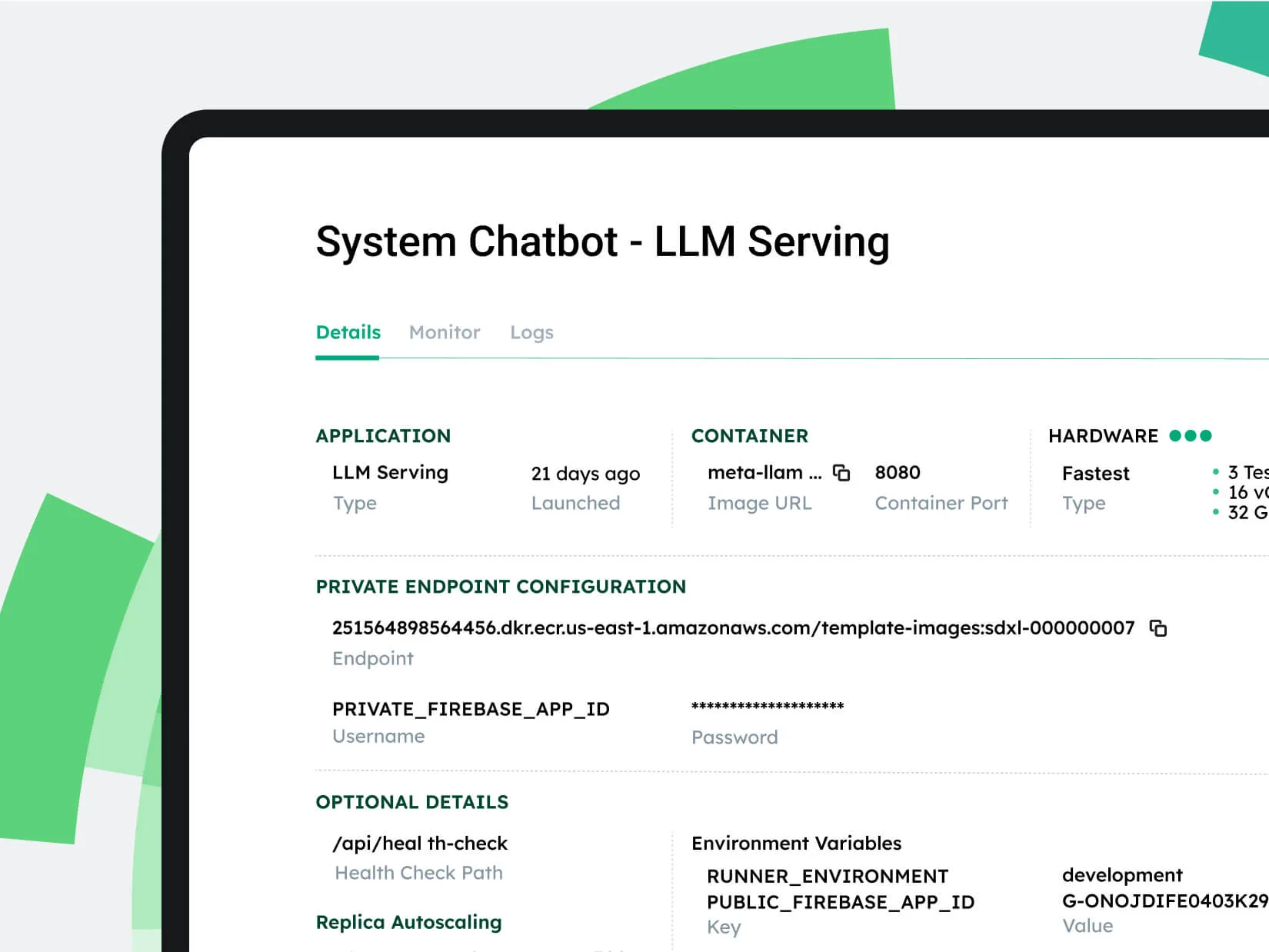
- Deploy open-source models on your preferred hardware and affordably scale usage with our platform optimizations.
Why Us?
How CentML Platform Works
Plan
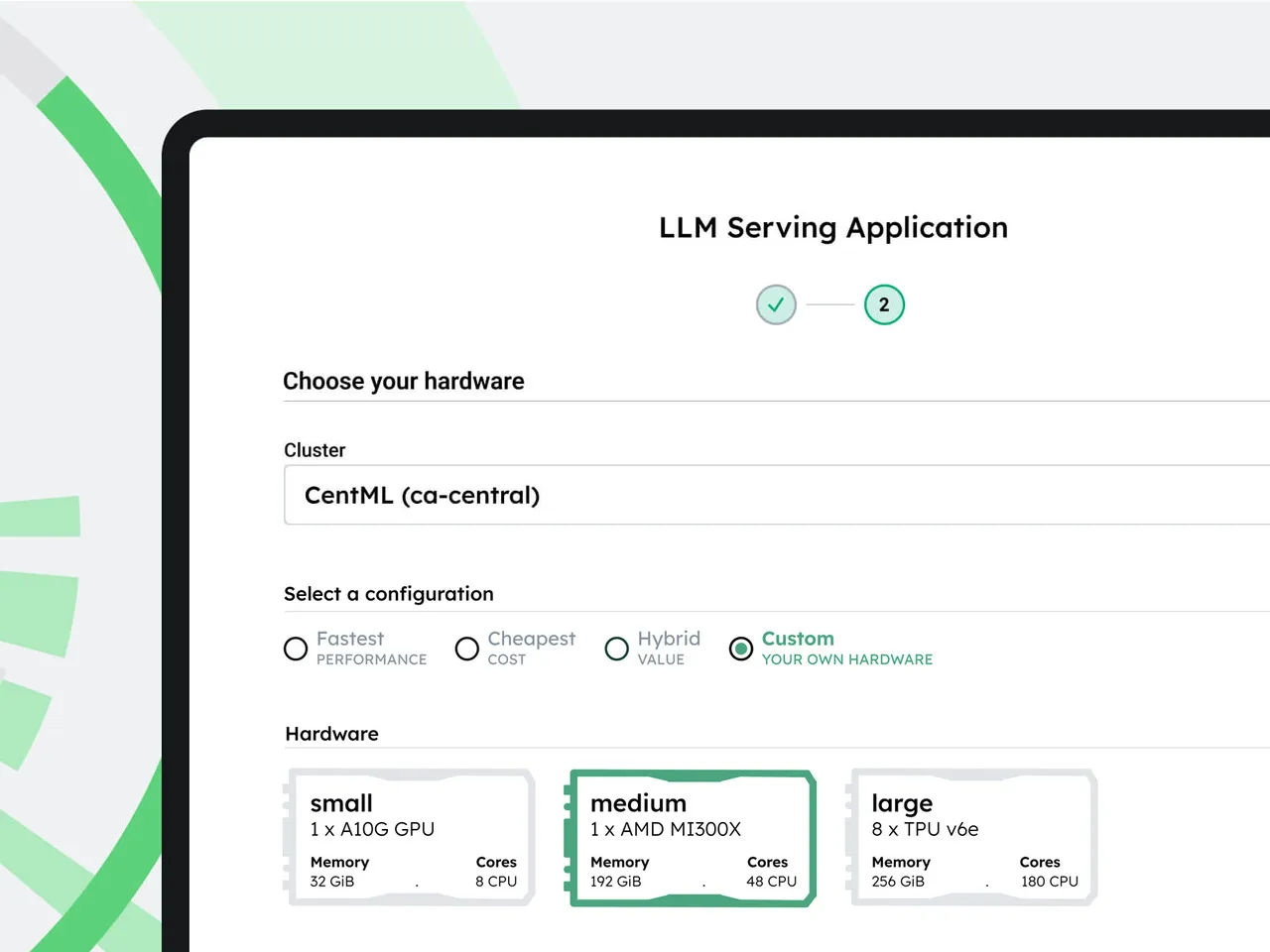
Input your model requirements, and CentML's Planner recommends the best hardware configurations and deployment strategies.
Optimize
The platform automatically applies optimizations to enhance performance and reduce costs across training, fine-tuning, and inference stages.
Deploy
Deploy your models with a few clicks on CentML's hosted infrastructure or your own. Create dedicated endpoints for easy integration with your applications.
Integrate
Leverage our ready-to-use app catalog to seamlessly incorporate your models into applications like RAG.
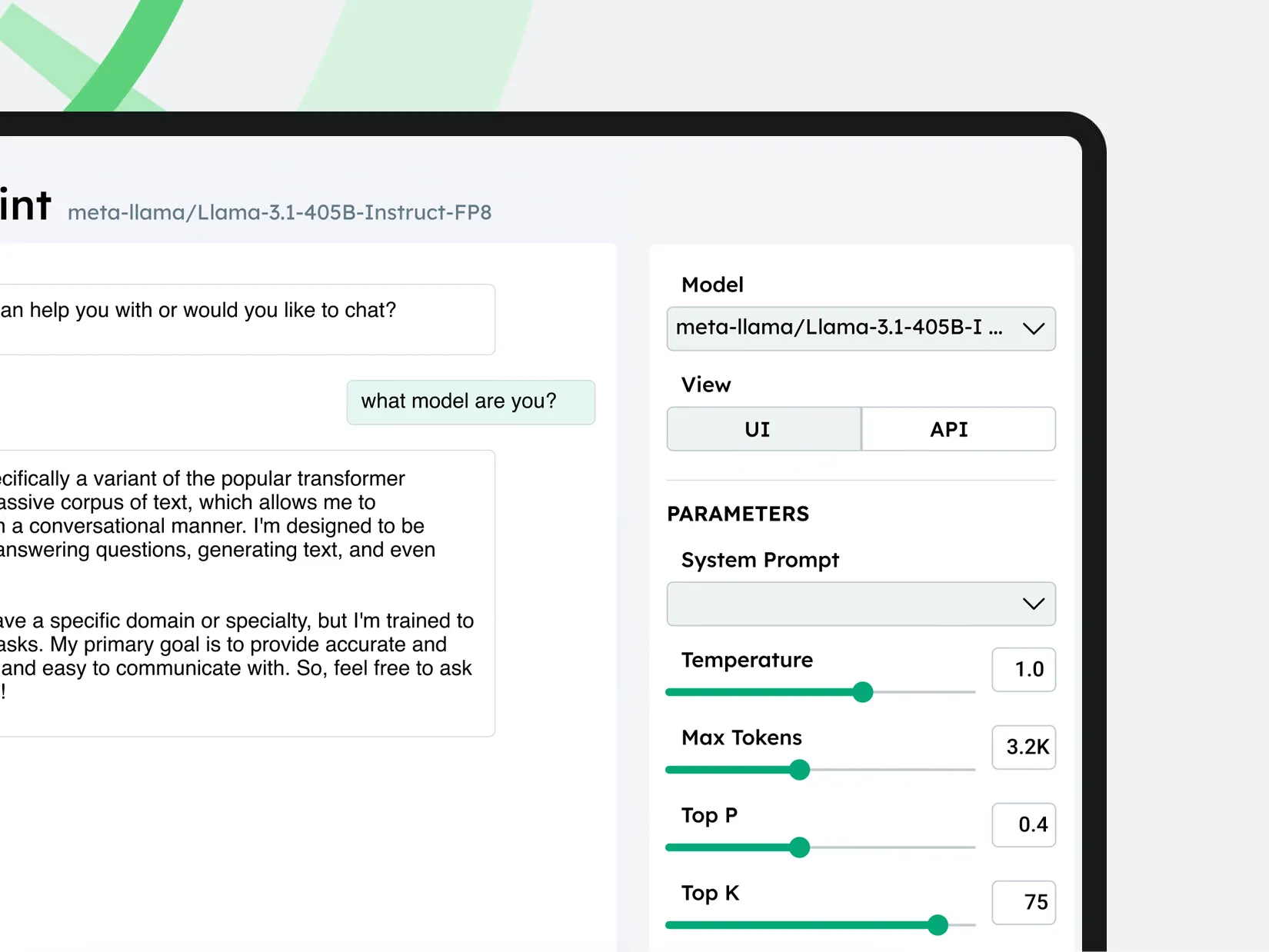
Flexible Deployment Options
Any Model, Any Hardware, Your Data
- Serverless Deployment:
- Automatically scale based on demand and pay only for the compute time you use.
- Bring Your Own Infrastructure:
- Deploy on your own cloud or on-premises infrastructure. We support all cloud providers' infrastructure.
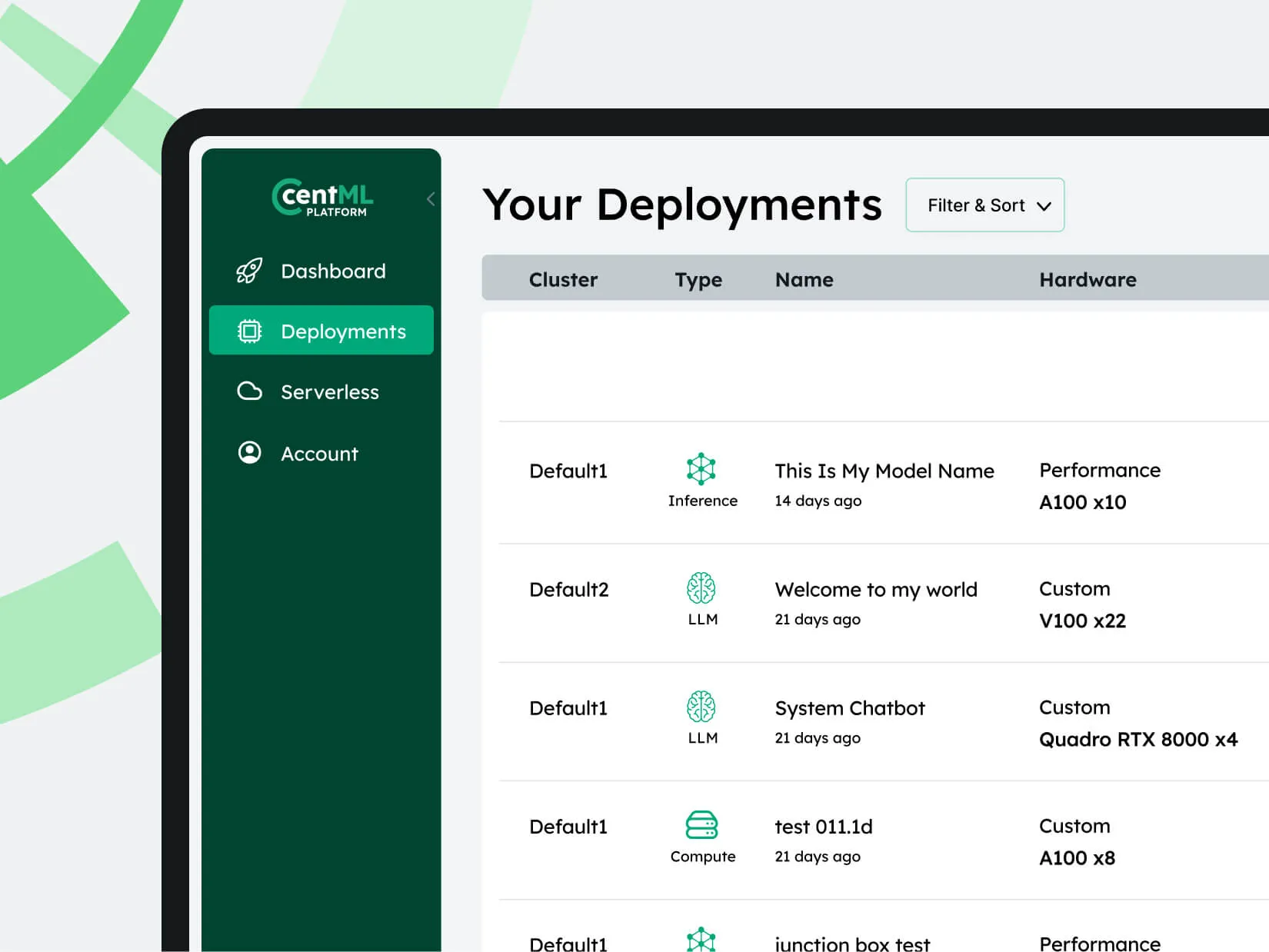
- Dedicated Endpoints:
- Ensure reliable and scalable access to your models across various environments.
- Hosted with CentML:
- Utilize our hosted infrastructure to deploy your models. We support all NVIDIA and AMD GPU, as well as TPUs.
- Pre-Packaged Solutions:
- Access our app catalog featuring pre-packaged pipelines for common use cases like Retrieval-Augmented Generation (RAG).
- Serverless Deployment:
- Automatically scale based on demand and pay only for the compute time you use.
- Bring Your Own Infrastructure:
- Deploy on your own cloud or on-premises infrastructure. We support all cloud providers' infrastructure.
- Dedicated Endpoints:
- Ensure reliable and scalable access to your models across various environments.
- Hosted with CentML:
- Utilize our hosted infrastructure to deploy your models. We support all NVIDIA and AMD GPU, as well as TPUs.
- Pre-Packaged Solutions:
- Access our app catalog featuring pre-packaged pipelines for common use cases like Retrieval-Augmented Generation (RAG).
Key Features
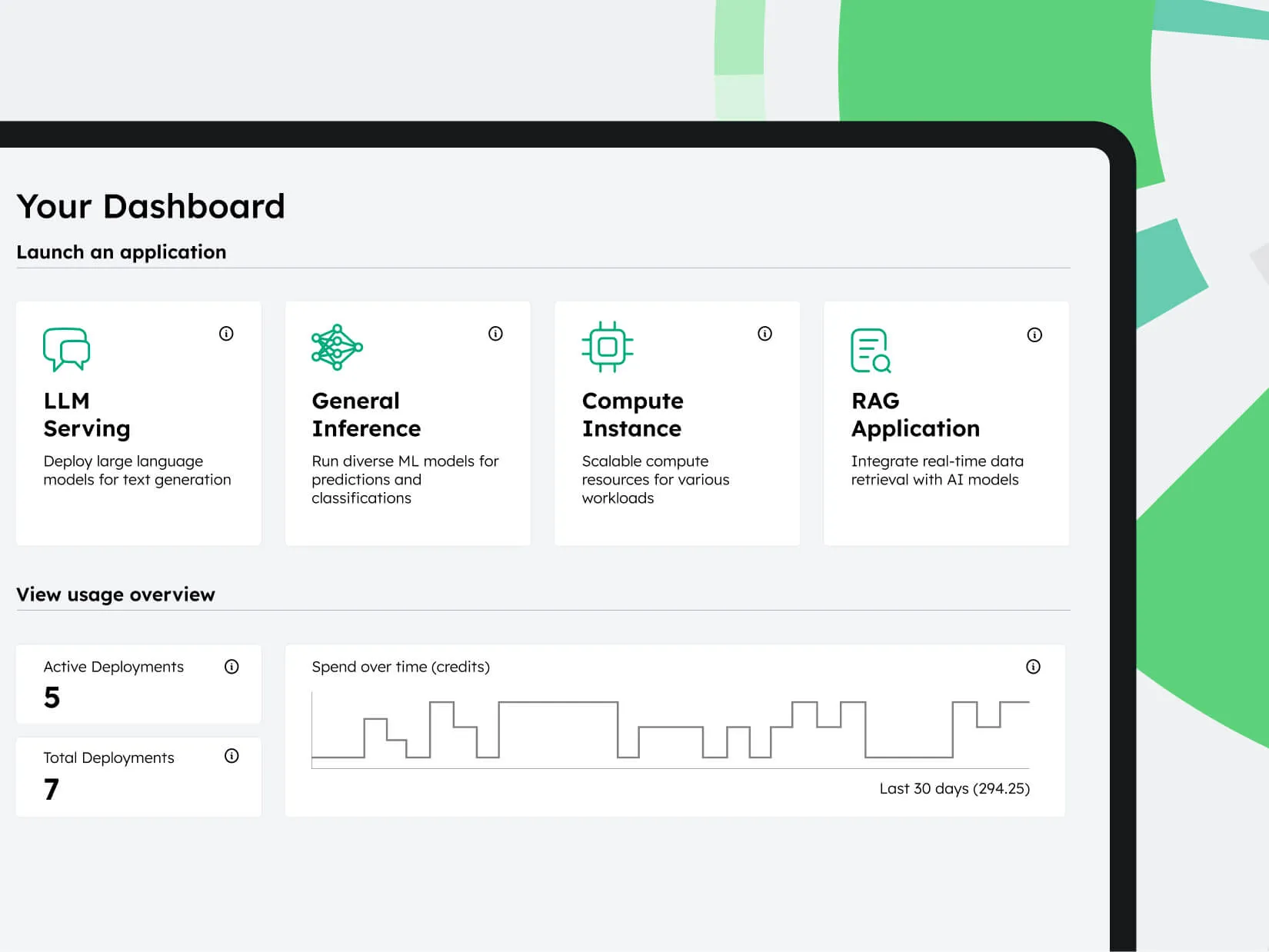
Planner
Know your deployment costs prior to launching your models.
Hardware Orchestrator
Manage your hardware clusters in a multi user environment.
Cost Efficiency
Reduce compute costs by intelligently selecting hardware and optimizing resource utilization.
Scalability
Effortlessly scale your AI operations with on chip, system-level and cluster-wide optimizations built-in.
Interoperability
Compatible with various hardware backends, both cloud-based and on-premises, and supports a wide range of ML frameworks and models.
User-Friendly Interface
Manage your deployment processes through an intuitive UI, minimizing the learning curve.
Success Stories
-
EquoAI
Discover how EquoAI achieved a 2.8x cost reduction on LLM deployment using CentML Platform. This case study reveals how CentML's tailored solutions empowered EquoAI to maximize performance while significantly lowering compute costs.
From Constraint to Competitive Edge: Exploring EquoAI's Tech Leap with CentML
- 2.8x
- reduction in compute costs
-
Advanced Hardware Utilization
See how CentML drove a 30% cost reduction and enhanced LLM performance on Oracle Cloud Infrastructure. This case study reveals how CentML's optimizations transformed large-scale AI deployment efficiency and effectiveness.
Maximizing LLM training and inference efficiency using CentML on OCI
- 30%
- cost reduction
-
GenAI Startup Support
Discover how CentML achieved up to 40% savings in ML training costs with advanced optimization techniques. This case study shows how CentML's solutions helped reduce expenses while maintaining top-tier model performance and scalability.
GenAI company cuts training costs by 36% with CentML
- 40%
- savings



Get started with CentML Platform
Ready to simplify your LLM deployment and accelerate your AI initiatives?
Deploy now
