Introducing ‘Tally’: A Novel Method of Efficient GPU Sharing for AI Workloads
The CentML team's latest paper, ‘Tally: Non-Intrusive Performance Isolation for Concurrent Deep Learning Workloads,’ has been awarded by ASPLOS 2025.

Table of Contents
Published: Oct 16, 2024
CentML is pleased to announce that the team’s latest paper, ‘Tally: Non-Intrusive Performance Isolation for Concurrent Deep Learning Workloads,’ has been awarded by ASPLOS 2025!
Architectural Support for Programming Languages and Operating Systems (ASPLOS), is a renowned conference that has served as a launchpad for many of the architectures that power our smartphones, cloud computing, and multi-core processors.
We’re excited that the team’s work is being recognized by ASPLOS, and we can’t wait to see how Tally will help address critical AI challenges — reducing costs and paving the way for further innovation across sectors.
Tackling GPU Underutilization in Deep Learning Clusters
The Tally paper addresses one of the most critical challenges in AI infrastructure: enhancing the efficiency of GPU usage while minimizing operational costs. Its authors — Wei Zhao (Machine Learning Engineer), Anand Jayarajan (Chief Architect), and Gennady Pekhimenko (CEO) — explain that GPU underutilization is a significant concern in production deep learning clusters, often leading to prolonged job queues and increased expenses.
A Non-Intrusive GPU Sharing Mechanism
The paper’s proposed solution, Tally, introduces a new GPU concurrency mechanism that allows multiple AI workloads to share GPUs effectively. This is done without compromising individual GPU performance or service-level guarantees.
Key features of Tally include:
- Fine-grained scheduling: Thread-block level GPU kernel scheduling mitigates interference between workloads and ensures strong performance isolation, preventing best-effort tasks from negatively impacting high-priority tasks.
- Non-intrusive integration: Tally requires no changes to existing applications, making it easy to integrate into current GPU clusters. The virtualization layer operates between application and GPUs, allowing for concurrent workloads.
- Generalizability: Tally can be applied across a diverse range of applications.
How Tally Works
Tally leverages advanced scheduling techniques that ensure efficient resource sharing without compromising latency-sensitive tasks:
- Kernel Slicing and Preemption: By using techniques like kernel slicing and preemption, Tally provides microsecond-scale turnaround latency. This allows it to promptly switch between high-priority and best-effort tasks while maximizing efficiency.
- Priority-aware Scheduling: Tally enables prioritization among scheduling of concurrent workloads by leveraging slicing, preemption primitives, and the transparent profiler.
Empirical Results: Boosting Throughput and GPU Sharing
Conducted on a diverse set of workload combinations, the paper demonstrates:
- Low-latency overhead: Tally maintains just a 7.2% latency overhead on critical tasks, compared to 345.5% and 188.9% exhibited by existing methods like NVIDIA MPS and Transparent GPU Sharing (TGS).
- Increased throughput: When compared to state-of-art GPU sharing systems, Tally significantly boosts throughput, resulting in a 1.6x increase in value.
Tally Was Built for Speed
Average Latency Overhead When Compared to Ideal Latency
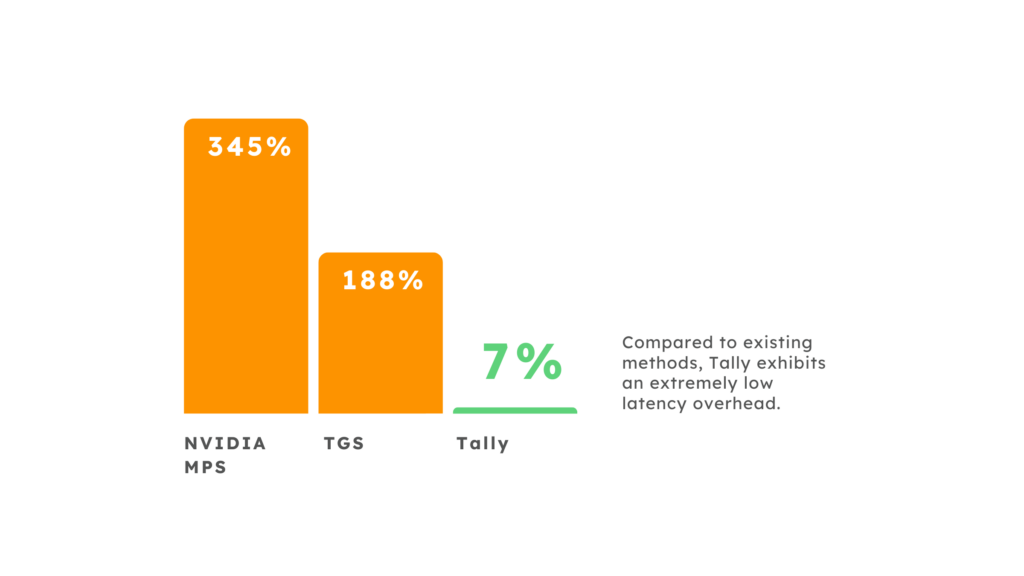
By improving throughput and reducing latency, Tally can significantly lower associated deployment costs, support AI scalability, and promote ongoing AI democratization.
Why Tally and GPU Sharing Matters
Tally’s ability to operate non-intrusively — while offering high performance — ensures compatibility with a wide range of deep learning workloads. As the AI ecosystem becomes more diverse, such broad compatibility becomes all the more critical.
Key benefits include:
- Maximizing hardware utilization: Efficiently shares GPUs across multiple workloads without the high integration costs seen in other methods.
- Seamless integration: Works with existing clusters as a plug-and-play solution, requiring no modifications to applications.
As GPU sharing becomes more crucial for scaling AI infrastructure, Tally offers a practical solution for maximizing hardware usage.
Stay tuned as the CentML team helps deliver highly efficient and scalable AI!
Meet the authors: Wei Zhao, Anand Jayarajan, Gennady Pekhimenko

Ready to supercharge your deployments? To learn more about how CentML can optimize your AI models, book a demo today.