Hardware Efficiency in the Era of LLM Deployments

Executive Summary (TLDR)
- The rise of Open Source Software Large Language Models (OSS LLMs) is driving a significant shift towards deploying powerful AI tools on internal infrastructures. This movement is fueled by the need for enhanced control, security, and privacy. However, the high cost associated with running LLMs, particularly on AI accelerators like NVIDIA GPUs, has sparked a keen interest in optimizing hardware usage to reduce costs.
- Despite the availability of more affordable options like the NVIDIA L4 and A10, their adoption for LLM inference is limited as current optimization strategies struggle to fully utilize their compute capacity, mainly due to memory and communication bandwidth constraints.
- The quest for the most efficient and economical way to deploy LLM services requires a complex trade-off between hardware choice, parallelism strategy, latency, and throughput. As workloads vary, navigating this complex trade-off is pivotal to achieving optimal performance for your LLM deployment.
- CentML’s CServe is designed to address these challenges
Introduction
Since the introduction of open-source foundational large language models (LLMs) like Llama, Mixtral, and Gemma, their widespread adoption has been driven by a need for privacy, control, and customization(e.g. code-llama). However, the sophisticated capabilities of LLMs require high computational resources. This need is compounded by a scarcity of the latest NVIDIA GPUs, which presents a dual challenge for companies: securing suitable hardware and efficiently implementing LLM serving technologies on these platforms.
The competitive push for cost-effective LLM inference services has led to a “race to the bottom” in pricing. Hosted solutions, while economical, often compromise on security, privacy, and service availability, making them unsuitable for enterprise needs. These services depend on economies of scale, which may lead to unsustainable pricing as model diversity increases. Additionally, the one-size-fits-all nature of the infrastructure and optimizations provided by these services often fails to meet specific LLM requirements efficiently.
We believe deploying LLMs on proprietary infrastructure—whether on-premises using Kubernetes or cloud-based via services like EKS and GKE—offers significant advantages. This approach allows companies to maintain control over hardware selection, cloud configuration, optimization, and integration, enhancing security, privacy, and cost-efficiency.
The principal challenge remains: deploying an efficient inference server that can achieve near-optimal performance for specific workloads and hardware configurations. To address this, we introduce CServe, a tailored solution designed to overcome the obstacles associated with private LLM deployment.
Challenges
Due to the high cost and low availability for the latest and greatest hardware, it is more economical to deploy LLMs on a variety of accelerators and cloud instances (also known as hardware heterogeneity). However, this comes at the cost of many additional challenges:
- Hardware availability/limitations: legacy and smaller GPUs (e.g. T4, L4, A10) offer much wider availability and competitive prices. However, to obtain better performance/dollar, additional optimizations are required to circumvent hardware constraints such as low memory capacity, weaker interconnects, and poor CPU performance.
- Complex trade-off between throughput, interactivity, and cost: the optimization strategy of various components (i.e. distributed inference, continuous batching, KV-cache management, etc) presents complex trade-offs between throughput, interactivity, and cost. As a result, the optimal configurations strongly depend on the specific use-case scenarios, making current optimization and benchmarking effort insufficient.
- Deployment complexity and scalability: the industry relies heavily on the “know-how” of a few system engineers for LLM optimization and deployment. While it may be sufficient for proof-of-concept systems, a production-level system requires a more robust, reproducible, and scalable deployment infrastructure to manage complex LLM tasks and optimizations.
Hardware constraints:
Let’s start with a simple comparison between a few widely available GPUs on major cloud service providers: NVIDIA L4, A100 and H100.
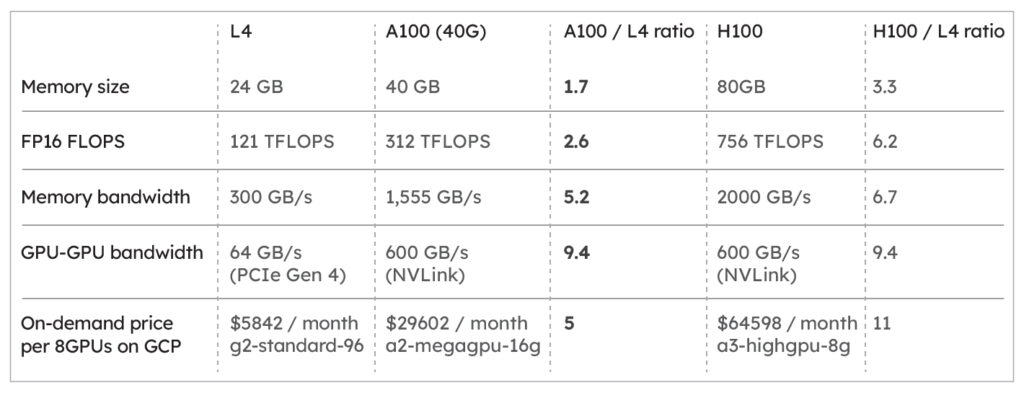
The A100 GPU significantly outperforms the L4, offering over 9 times the inter-GPU bandwidth and over 5 times the memory bandwidth, addressing two critical bottlenecks in LLM inference: the need for multi-GPU setups and handling large model sizes.
The cost differential is disappointing, with the A100 priced at approximately 5 times that of the L4, it appears that we would be getting worse performance / dollar if the performance is bottlenecked by memory bandwidth or inter-GPU communication. This raises a crucial question: Can multiple L4 GPUs match the performance of a single A100 at a lower cost? Clearly, without optimization, stacking L4 GPUs doesn’t suffice due to excessive communication overhead that severely hampers efficiency.
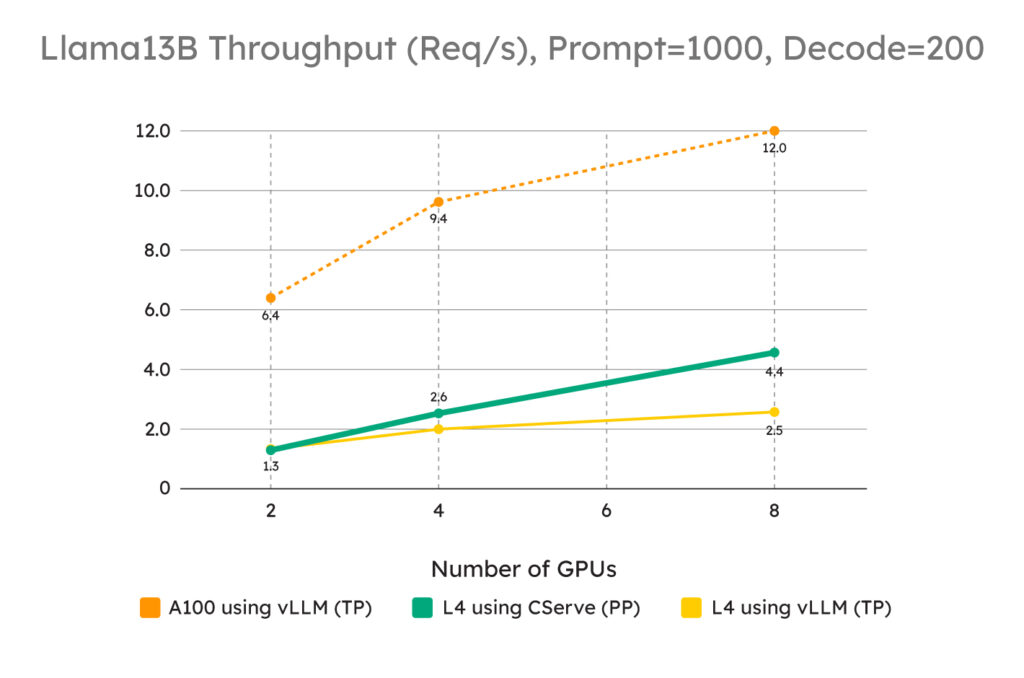
However, CServe changes the equation. By implementing optimization strategies such as pipeline parallelism, throughput-oriented request scheduling, and memory access optimizations, CServe reduces the communication load and expands memory utilization for key-value caching. This pushes performance bottleneck towards compute, and allows multiple L4 GPUs to surpass the performance per dollar of A100s in large-scale deployments, achieving up to 1.8 times the throughput of traditional setups.
Figure 1. Below shows how inferencing with CServe with multiple L4 GPUs can outperform vLLM in throughput for up to 1.8x. For large scale experiments, using A100 GPUs no longer shows better throughput/dollar than L4 GPUs, as A100 GPUs only give 2.7x performance boost with more than 5x price.
Hardware limitations can also make it impossible to deploy models that cannot fit into the GPU memory of your system. In addition to better cost, CServe also comes with optimization for extremely hardware-constrained systems. With CServe, you can deploy a much larger model on smaller GPUs that are otherwise impossible. For example:
- Deploying a Llama2-13B model in float16 precision on a single L4, A10, or RTX3090 GPU
- Deploying a Mixtral-8x7B model using 4 A10/L4 GPUs
This capability makes less advanced and more readily available GPUs a practical option for LLM inference, providing a cost-effective alternative to waiting for high-end GPUs like the A100.
Complex Trade-offs
Optimizations for LLMs typically involve trade-offs. For instance, CUDAGraph enhances execution latency on GPUs but uses more memory, which could reduce throughput at high request volumes. Similarly, paged attention decreases memory usage for continuous batching but can add latency and complexity, particularly in scenarios with low request rates.
Assessing the performance of an LLM serving system extends beyond just latency or throughput. Comprehensive evaluation should include metrics like time-to-first-token (TTFT), time-per-output-token (TPOT), and both median and worst-case latencies across various request rates, use cases, and hardware setups.
Cost is also a critical factor. While high-end GPUs such as the A100 and H100 are preferred for their performance, they come with high costs and may not always be available. New optimizations can make lower-end GPUs viable for large-scale deployments by enhancing their cost-effectiveness, particularly in scenarios that are less sensitive to latency.
To navigate these complex trade-offs, we’ve developed the CServe Planner. This tool enhances CServe’s core offerings—privacy, control, and efficiency—by enabling precise cost-management and performance optimization. Key features include:
- A benchmarking tool for gathering comprehensive and accurate performance data that tracks real-life use cases without the need for an actual deployment
- An analytics dashboard to visualize various performance trade-offs across deployment strategies to further optimize the system against your use cases
- A one-click deployment to execute deployment plans at scale, with performance guarantees.
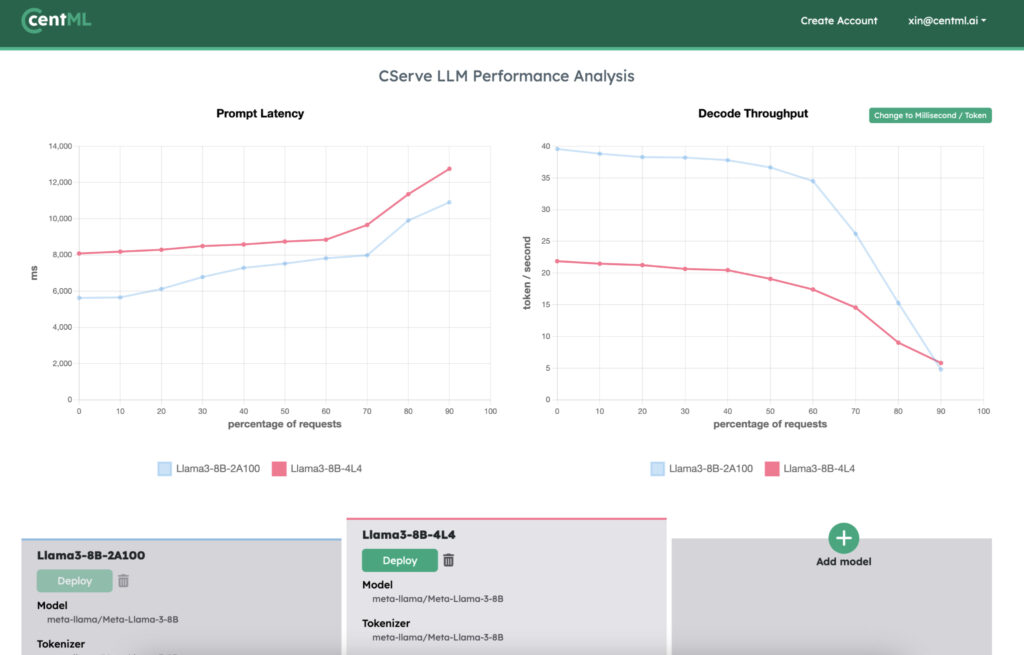
Case-study: trade-off between different parallel inference strategies
Using multiple GPUs to serve LLMs (also known as distributed inference) is necessary for deploying large-scale models. It comes with many advantages, including:
- serving larger models by splitting model weights across many GPUs
- handling very long context and more requests at the same time due to increased KV-cache size
- reducing latency, increasing throughput, and oftentimes both
In choosing a parallelization strategy, the feasibility often depends on the size of the model’s parameters. If the model cannot be fully accommodated on a single GPU due to memory constraints, we use model parallelism, splitting the model across multiple GPUs. This approach includes tensor parallelism (TP), which distributes model weights to enlarge the KV-cache and decrease latency, and pipeline parallelism (PP), which segments the model into different stages across GPUs to boost throughput. If the model fits within the memory of the GPUs used, additional GPUs can be employed through data parallelism (DP), where requests are balanced across the GPUs by duplicating the model weights.
Choosing the right number of GPUs and the type of parallelism involves navigating complex trade-offs. The table below shows the impact on performance when choosing different strategies of distributed inference.

There isn’t a one-size-fits-all strategy; the best approach depends on specific workload requirements and available hardware. For instance, throughput-oriented tasks on lower-end GPUs or multi-node setups might benefit more from PP due to its lower communication demands compared to TP. However, some scenarios might still require TP (along with other optimizations) to manage latency effectively, albeit at a throughput cost.
The optimal strategy often combines various techniques to balance cost against performance constraints like latency. With CServe, this complex decision-making process is greatly simplified and automated, empowering users to optimize their deployments without needing to master the underlying engineering complexities. CServe integrates CentML’s expertise in CUDA kernel optimization, compilers, and distributed systems with the user’s specific needs concerning workload, budget, and machine learning expertise, to enhance the efficiency and cost-effectiveness of LLM deployments.
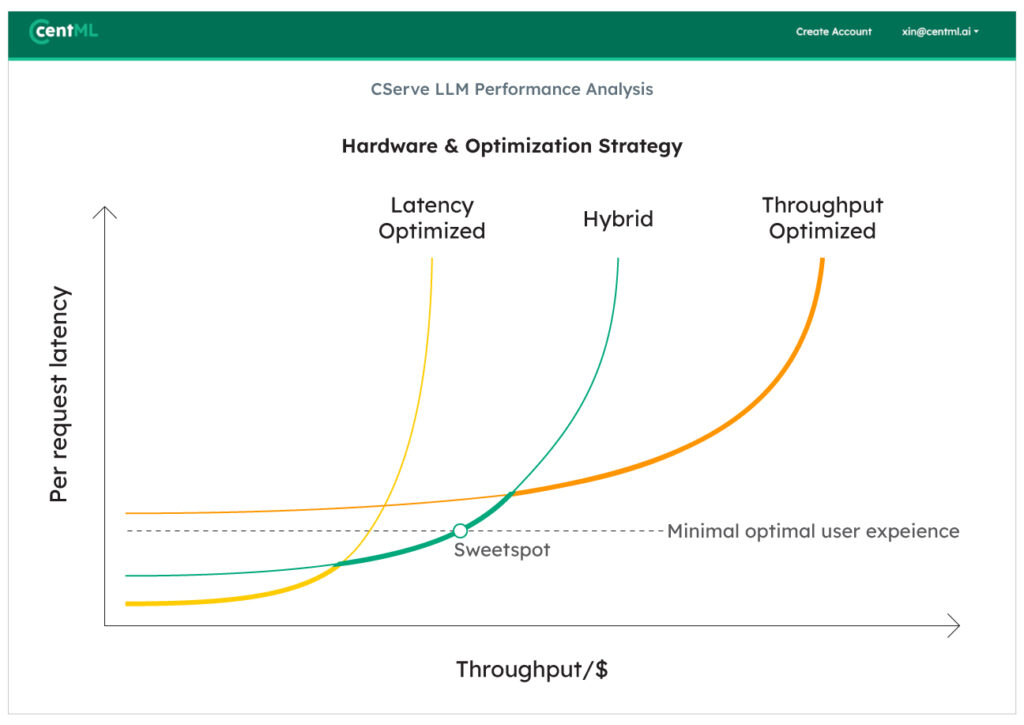
CServe: your LLM inference framework with control, privacy, and efficiency
The recency of LLMs and need for rapid development has left performance optimization for these workloads a myth for many practitioners. At CentML, we believe in democratizing machine learning through offering system-level optimizations at mass.
CServe is our first attempt for this mission:
- Through the CServe LLM inference engine, we unlock additional hardware capacity for lower-grade and consumer grade GPUs. Our optimizations not only focus on latency and throughput, it also lowers both the cost and barrier of entry for those wishing to deploy LLMs at scale.
- Through deployment planner, we allow our users to join us for performance optimization: asking users to provide what they know best (workload, hardware constraints, budget, etc), automating and providing the best optimizations possible, and finally, presenting users on what they care the most: (user experience and cost).
The journey does not end there, CServe is designed to be deployed at scale. With just a few buttons/commands, CServe makes it easy to record and reproduce an optima LLM deployment at scale, either locally through Кubernetes, or in the cloud through ECR, GKE, Snowpark Container Services, etc.
CServe is currently in private preview. Please send us an email at cserve-dev@centml.ai for early access.

Share this

