A Fine-Tuning Breakthrough: CentML’s New Sylva Method Revolutionizes LLM Adaptation
Learn about CentML’s next-gen fine-tuning, which will take your LLM performance to new heights.

Background: The Impact of LLM Fine-Tuning on Business
Fine-tuning of Large Language Models (LLMs) has become a critical process for achieving business intelligence and operational efficiency. By tailoring pre-trained LLMs to the unique characteristics of application datasets, businesses are now able to build high-performance LLMs for critical applications like assessing financial risk and parsing legal contracts.
Fine-tuning not only optimizes the accuracy of such models, it also ensures models are seamlessly aligned with the enterprise and its applications. By embracing fine-tuning, enterprises can unlock the potential of the latest powerful LLMs, driving innovation and delivering exceptional products and services.
Now, we’re taking fine-tuning to the next level.
The Next Generation of Fine-Tuning: Sylva
The CentML team is thrilled to introduce Sylva, a groundbreaking method for LLM fine-tuning that sets a new standard for AI adaptation.
Engineered to deliver high performance and high-quality models, Sylva leverages second-order information (indicating weight redundancy) and numerical linear algebra algorithms to provide significant speedup in LLM fine-tuning without compromising accuracy.
This method sets a new standard in the field. We are confident it will drive your innovations further — allowing AI to adapt to diverse and dynamic enterprise needs.
How it Works: From Full LLM Fine-Tuning to Sylva
The Full Fine-Tuning Approach
The naive fine-tuning approach, known as full fine-tuning (Figure 1), trains all of the weights in the pre-trained LLM on application-specific datasets during adaptation.
Full fine-tuning achieves high model quality for business-specific tasks. However, it requires the same hardware memory capacities as the pre-training process.
Zero Redundancy Optimizer (ZeRO) is a memory-efficient implementation of the full fine-tuning approach. Although it reduces the per-GPU device memory footprint, it introduces extra communication overheads across GPUs.
Low-Rank Adaptation
Low-Rank Adaptation (LoRA) (Figure 1) freezes the pre-trained weights and injects a small number of trainable weights as low-rank decompositions to each layer of the pre-trained LLM.
After fine-tuning, the injected trainable weights are merged with the frozen weights via summation. LoRA attains high model quality since the pre-trained weights of the LLM are frozen and can be merged with task-specific knowledge. Moreover, it improves fine-tuning performance compared to ZeRO, since only the injected trainable weights are trained during the fine-tuning process.
However, LoRA introduces extra computation. The injected trainable weights and the frozen weights are processed separately in the forward and backward passes.
CentML’s Sylva LLM Fine-Tuning Method
Sylva (Figure 1) leverages second-order information to identify a small number of important weights of the pre-trained LLM in a lightweight pre-processing step. The pre-processing results can be reused across multiple fine-tuning jobs, and thus the cost of pre-processing can be amortized.
In the fine-tuning process, only the sparse weights identified in the pre-processing step are trained, the pre-trained weights are kept frozen. Moreover, Sylva embeds the sparse trainable weights into the frozen weights during the fine-tuning process to eliminate the extra computation introduced by LoRA. Thus, it provides better fine-tuning performance, while attaining high model quality.
Sylva offers several advantages:
- Improves fine-tuning performance on emerging LLMs: on average 5.1x speedup compared to ZeRO and 1.2x speedup compared to LoRA.
- Provides high model quality: comparable quality to full fine-tuning and LoRA on a wide range of sparsity.
- Has no additional inference overheads compared to full fine-tuning and LoRA methods.
- For example, fine-tuning LLaMA-7B with Sylva (98.4% sparsity) improves 5-shot MMLU evaluation accuracy from 32.9 to 38.1 in about 100 minutes on a NVIDIA L4 GPU.
Comparing Approaches
Sylva identifies and trains only a small subset of important weights (‘sparse trainable weights’), embedding them into the frozen weights. This eliminates the need for extra computation and enhances overall performance.
Full Fine-Tuning trains all model weights, which delivers high task-specific performance but introduces communication overhead across GPUs. Low-Rank Adaptation freezes pre-trained weights and trains smaller injected weights. This improves efficiency but introduces extra computation during forward and backward passes.
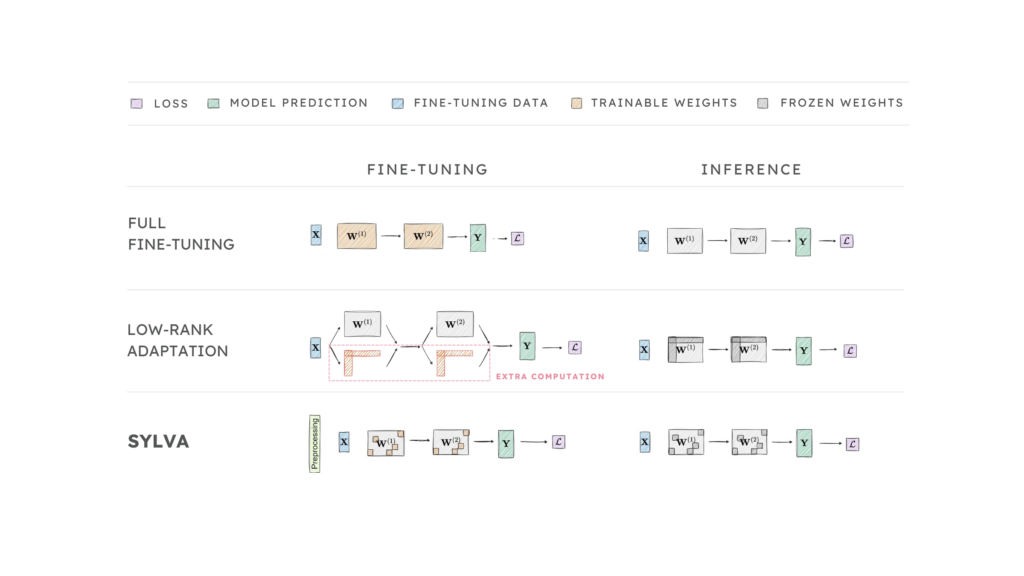
Figure 1. Comparing Full Fine-Tuning, LoRA, and Sylva Approaches
Comparative Study: Sylva Performance & Quality
We compare all three methods ZeRO, LoRA and Sylva with GPT-2 Large (E2E NLG challenge Dataset), LLaMA-3B and LLaMA-7B (OpenAssistant Conversations Dataset) using up to 16 NVIDIA L4 GPUs.
Sylva’s Fine-Tuning Performance
Figure 2 presents the end-to-end fine-tuning execution time per iteration using up to 16 GPUs with 4 nodes.
Sylva provides significant performance speedups over ZeRO full fine-tuning by 3.6x, 5.3x, 6.4x on GPT-2 Large, LLaMA-3B and LLaMA-7B models, respectively. Sylva outperforms LoRA by 1.1x, 1.2x, 1.4x on GPT-2 Large, LLaMA-3B and LLaMA-7B models, respectively.
Comparing Fine-Tuning Times
(Milliseconds)
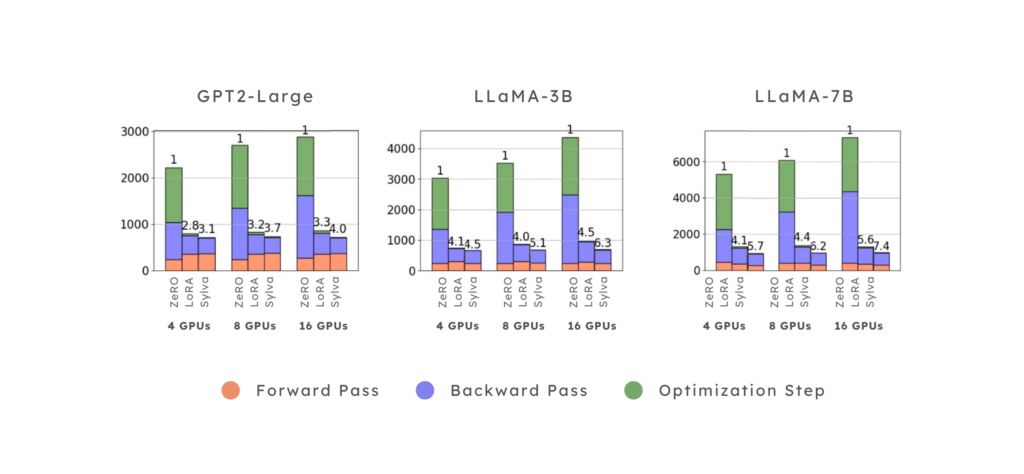
Figure 2: Fine-tuning time (in milliseconds) per iteration (Y-axis) on GPT-2 Large, LLaMA-3B, and LLaMA-7B, as the number of GPUs (X-axis) increases from 4 to 16. The fine-tuning time is broken down into forward pass time (orange), backward pass time (purple) and optimization step time (green).
Sylva’s Model Quality
Table 1 presents the model quality achieved by ZeRO full fine-tuning, LoRA and Sylva with GPT-2 Large, and LLaMA-7B at a high sparsity level of 99.5%. Sylva achieves comparable model quality with ZeRO full fine-tuning and LoRA.
Furthermore, we extensively evaluate the robustness of Sylva and LoRA on various levels of sparsity in 86.7%-99.5% with GPT-2 Large. With a sparsity of 86.7-96.7% sparsity, Sylva achieves comparable or slightly better model quality than LoRA.

Table 1: Model quality between full fine-tuning, LoRA, and Sylva on GPT-2 Large (E2E NLG challenge Dataset) and LLaMA-7B (OpenAssistant Conversations Dataset ).
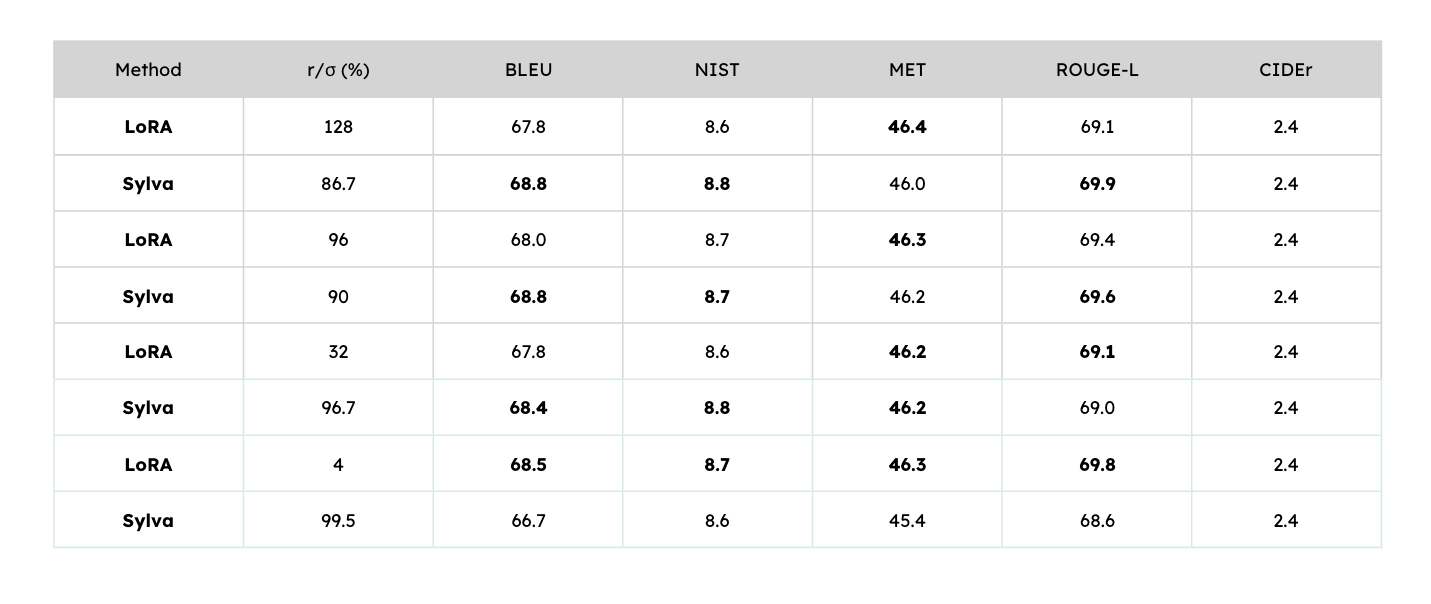
Table 2: Model quality of LoRA and Sylva at various levels of sparsity on GPT-2 Large (E2E NLG challenge Dataset).
New Standards for AI Adaptability
These advancements in LLM fine-tuning redefine the standards of AI adaptability and cost-effectiveness for various business applications. By enhancing the flexibility of AI, we aim to effectively address diverse industry needs and support ongoing innovation.
We invite you to dive into the details by reading our recently published research article at ICS 2024, and our open-source code repository.
We encourage you to join us in pushing the boundaries of what adaptable AI can achieve. By releasing our achievements as open source, we aim to empower the AI community to drive further innovations.
Thank you for reading about our innovation journey, and here’s to the future of adaptable AI!
Ready to Supercharge Your LLM Deployment? To learn more about how CentML can optimize your AI and ML models, book a demo today.

Share this

