A Technical Deep Dive into Pipeline Parallel Inference with CentML
We're excited to announce the implementation of pipeline parallel inference in vLLM, a contribution that's redefining how we deploy and run massive language models.

With yesterday’s release of Llama-3.1-405B, we’re excited to announce that CentML’s recent contribution to vLLM, adding pipeline parallel inference support, has significantly improved performance when deploying Llama-405B on multi-node setups with vLLM.
We’re proud to join many other open-source contributors in the vLLM community, making Llama 3.1 405B available on the day of its release. More importantly, our contribution marks a significant milestone in our ongoing commitment to democratize machine learning and make LLMs more efficient and affordable for all.
What pipeline parallelism brings to LLM inference optimizations:
Pipeline parallelism is a technique enabling distributed serving of LLMs and machine learning models. It works alongside tensor parallelism, the main distributed inference paradigm already present in vLLM. While tensor parallelism operates within a layer, pipeline parallelism partitions model layers into multiple stages. These stages can then be assigned to different GPUs, as shown in the image below. This approach allows each GPU to be responsible for a smaller portion of the model, enabling the serving of larger models than would be possible with a single device.
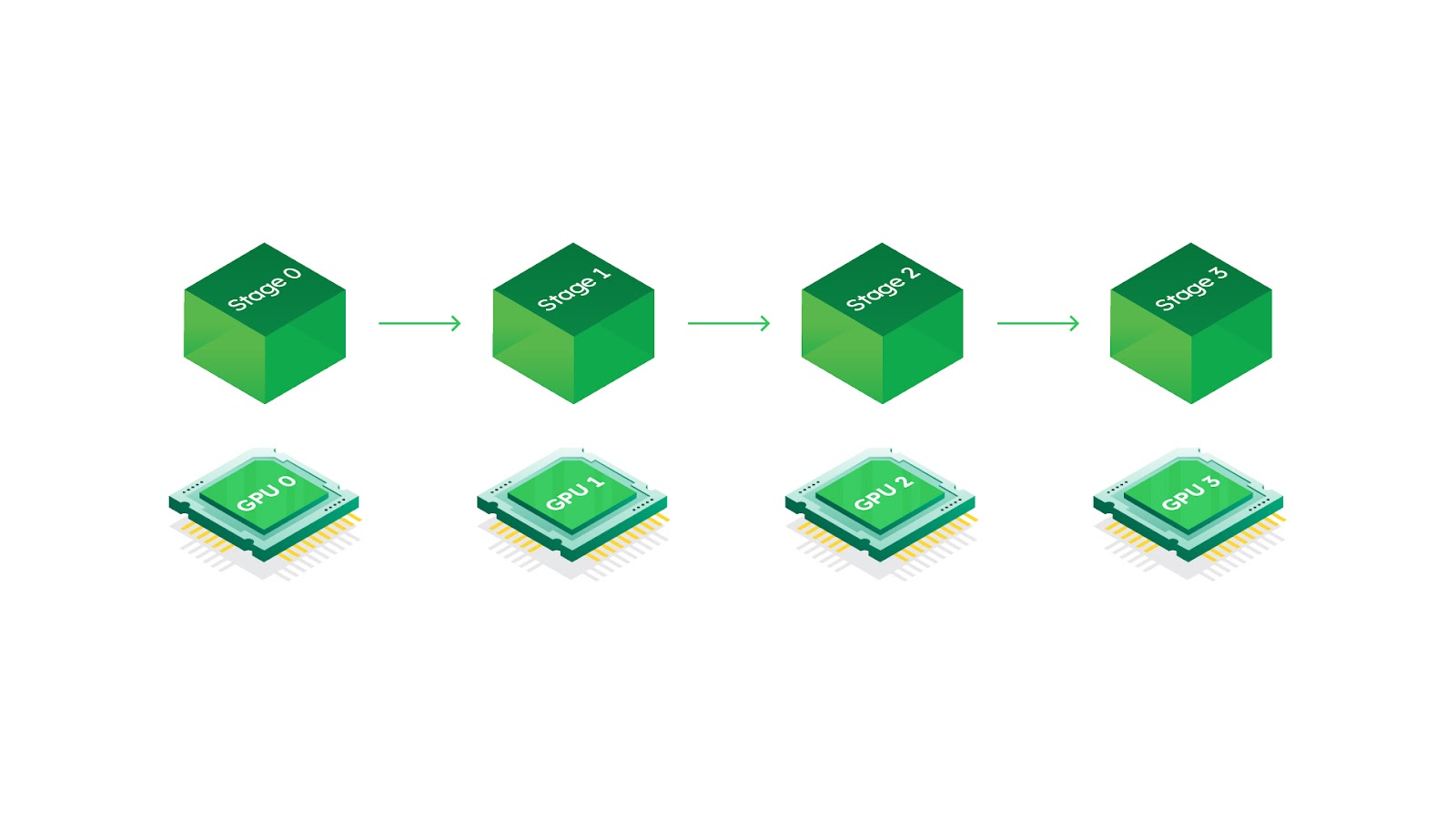
Implementing pipeline parallelism involves major changes to vLLM’s architecture:
Model Splitting: We split the model into multiple stages to be served by each device. This is accomplished by creating only the layers corresponding to each stage on each device and replacing the rest with dummy layers (For example, we have 4 devices and 28 layers. The first device should only load the first 7 layers). This ensures that each device only loads the weights it’s responsible for.
Worker Communication: We added code at the Worker level to allow workers to send and receive intermediate states between them, leveraging the PyTorch distributed library to stitch together the full model.
Multiple Request Streams: A significant change is supporting different request streams simultaneously. Unlike tensor parallelism, where all workers execute the same request stream concurrently, pipeline parallelism requires each stage to execute the same request stream at different times. This poses two main challenges:
- Ensuring data dependencies are respected (the next iteration of a request should only be scheduled after completing the previous iteration of the request).
- Keeping all workers fully occupied for efficient execution.
We solved these challenges by introducing “virtual engines” – an implementation of separate request streams. Each virtual engine consists of a separate scheduler and its own KV cache. New requests are assigned to a virtual engine and remain there until completion. This allows each virtual engine to be independently scheduled and executed concurrently with others using Python’s asyncio. The execution timeline of different virtual engines on each worker can be seen in the below diagram, showing how both challenges can be satisfied.

Best Practices
To take advantage of pipeline parallelism in vLLM, follow these best practices:
- Specify the “– – pipeline-parallel-size” Parameter: When launching vLLM serve for your model, define the size of your pipeline parallelism.
- Optimize Node Utilization: Enable pipeline parallelism across nodes and set the tensor parallelism size to match the number of GPUs within a node.
- Leverage Chunked Prefill: Compatible with pipeline parallelism, setting an appropriate chunked prefill size can further enhance performance.
For more details, check out the vLLM documentation.
Benchmarks
We conducted preliminary benchmarks on the latest vLLM mainline as of July 22. For this benchmark we use 2 g4.24xlarge instances (4 L4s) from AWS coupled in a multi-node configuration. For tensor parallel benchmarks we use 8-way tensor parallel, while for pipeline parallel, we use 4-way tensor parallel with 2-way pipeline parallel. We benchmark on 1k prompt tokens and 128 decode tokens on Llama 3 70B with a max context length of 4k and “– – gpu-memory-utilization” set to 0.85.
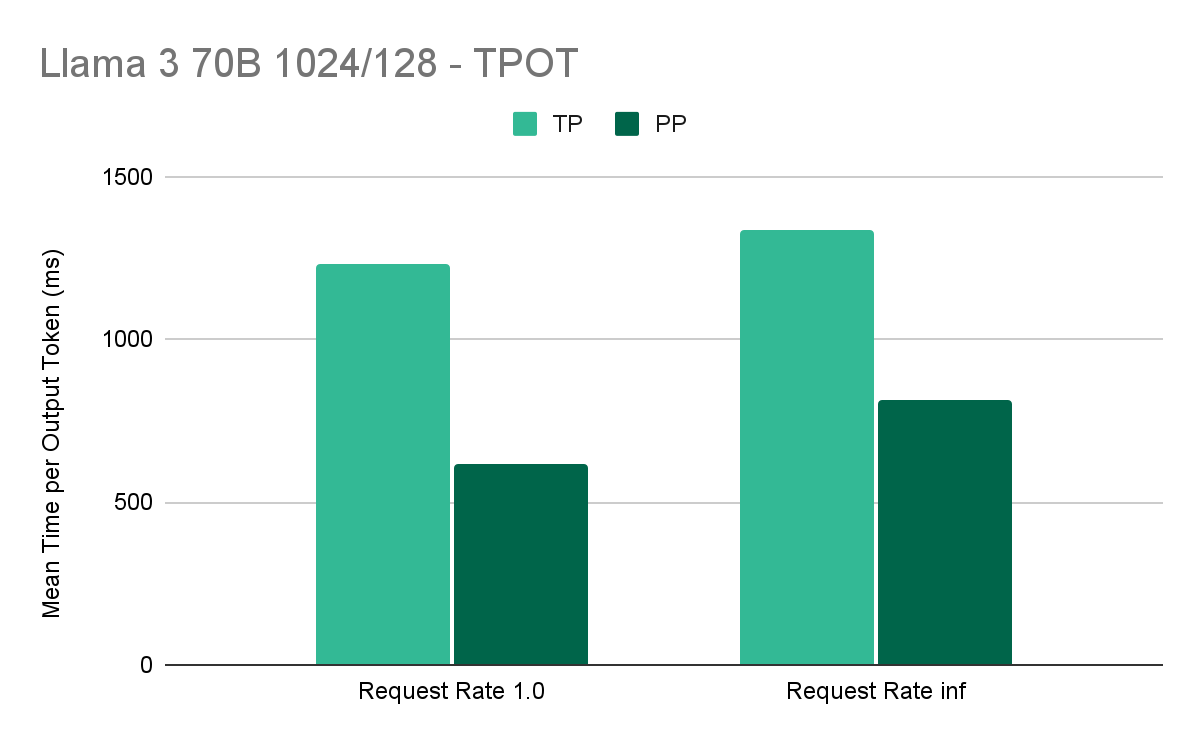
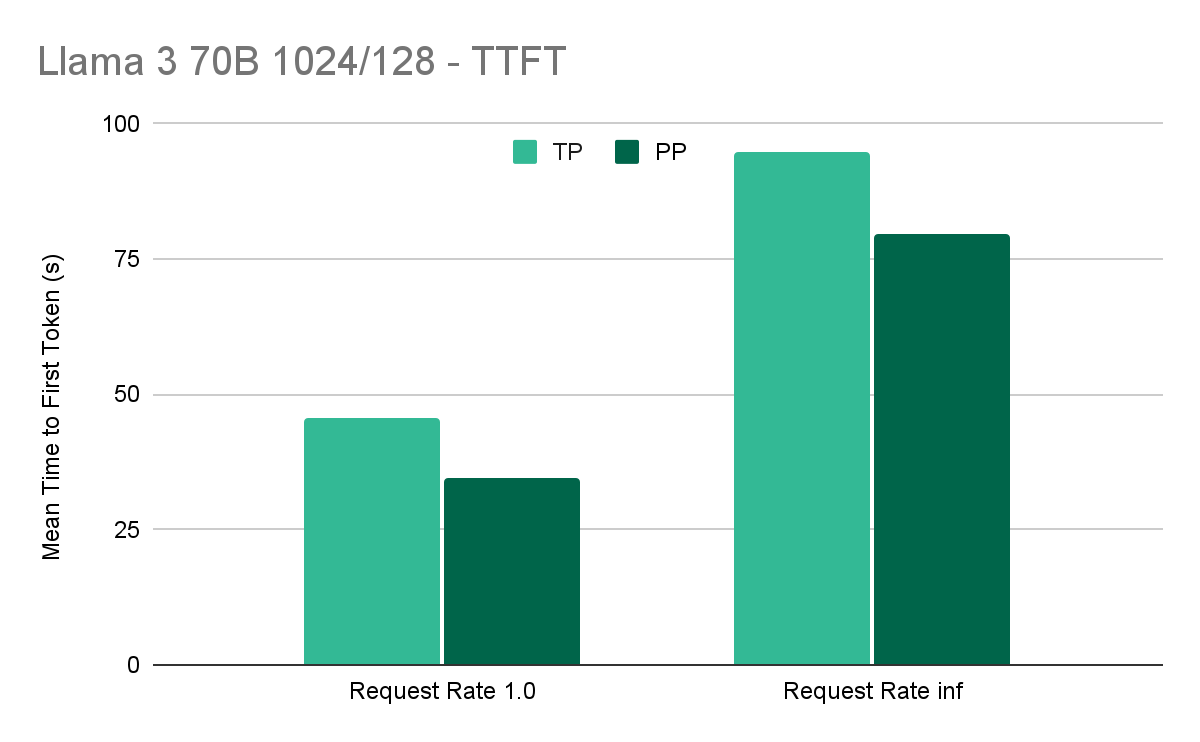

Acknowledgments
This work is only possible due to our amazing collaborators on the vLLM team from UC Berkeley, UC San Diego, IBM, Anyscale, and Snowflake.
Conclusion
CentML’s integration of pipeline parallelism into vLLM marks a significant leap forward in the deployment of large language models like Llama-3.1-405B. By harnessing the power of multi-node setups, we are making advanced AI more accessible, efficient, and cost-effective for everyone—from individual developers to large enterprises.
Our commitment to the open-source community and continuous innovation drives us to push the boundaries of what’s possible in machine learning. We invite you to explore these advancements, try out Llama-3.1-405B, and join us in shaping the future of AI.
Stay tuned for more updates, detailed guides, and success stories. Together, we can democratize AI and unlock its full potential. Thank you for being a part of this journey. For more information, please contact us at sales@centml.ai or the LinkedIn

Share this

