Build Your AI Models with
Ease and Efficiency
Train and deploy your own ML models while reducing compute and
maintaining model accuracy.
Trusted by











![]() Cost Effective
Cost Effective
More efficient cycles means reduced costs.
![]() Faster
Faster
Experience up to 8x acceleration of your model inference.
![]() Safer
Safer
Model code and accuracy stay intact.
Deploy with the fastest and the most cost efficient platform
Elevate performance while curbing costs with CentML. Enhance GPU efficiency, slash latency, and boost throughput effortlessly. Deploy with CentML and make computing cost-effective and powerful.
A leading AI company in the pricing of financial derivatives
~$65,280
In monthly savings
3x-65x
Depending on the model and hardware choices
A top financial AI company partnered with CentML, gaining a 65x performance boost using consumer-grade GPUs and CentML's technology. This reduced costs significantly, outperforming Intel's CPUs by 10x with a 15x cost advantage. CentML's optimizations resulted in a 1.5x inference speedup, optimizing CPU resources and delivering cost savings for the client's financial operations.
AI company specializing in foundational models
~$46,540
In monthly savings
1.75x-7x
Depending on the model and deployment platform choices
An AI firm, with roots in AI research, teamed up with CentML to boost inference speed by 65% and increase throughput nearly 7x for large LLMs. Traditional methods caused delays, but CentML's Hidet compiler provided a solution with GPU kernel optimization. Clients surpassed SLAs, enhancing their AI models' efficiency.
Generative-AI company specializing in conversational knowledge analysis
~$66,532
In monthly savings
1.7x-2x
Inference acceleration
A conversational AI company partnered with CentML, achieving a 2x model inference speedup and 50% throughput improvement with NVIDIA V100 GPUs. CentML's graph optimization resulted in over 2x speedup on small batch sizes and a 1.7x improvement on larger ones. They overcame GPU challenges with Microsoft DeepSpeed. This partnership enhances their API-as-a-Service, providing a superior customer experience.
Meet CServe
Revolutionizing model serving for the LLM era with unparalleled speed, cost-efficiency and simplicity.
Learn More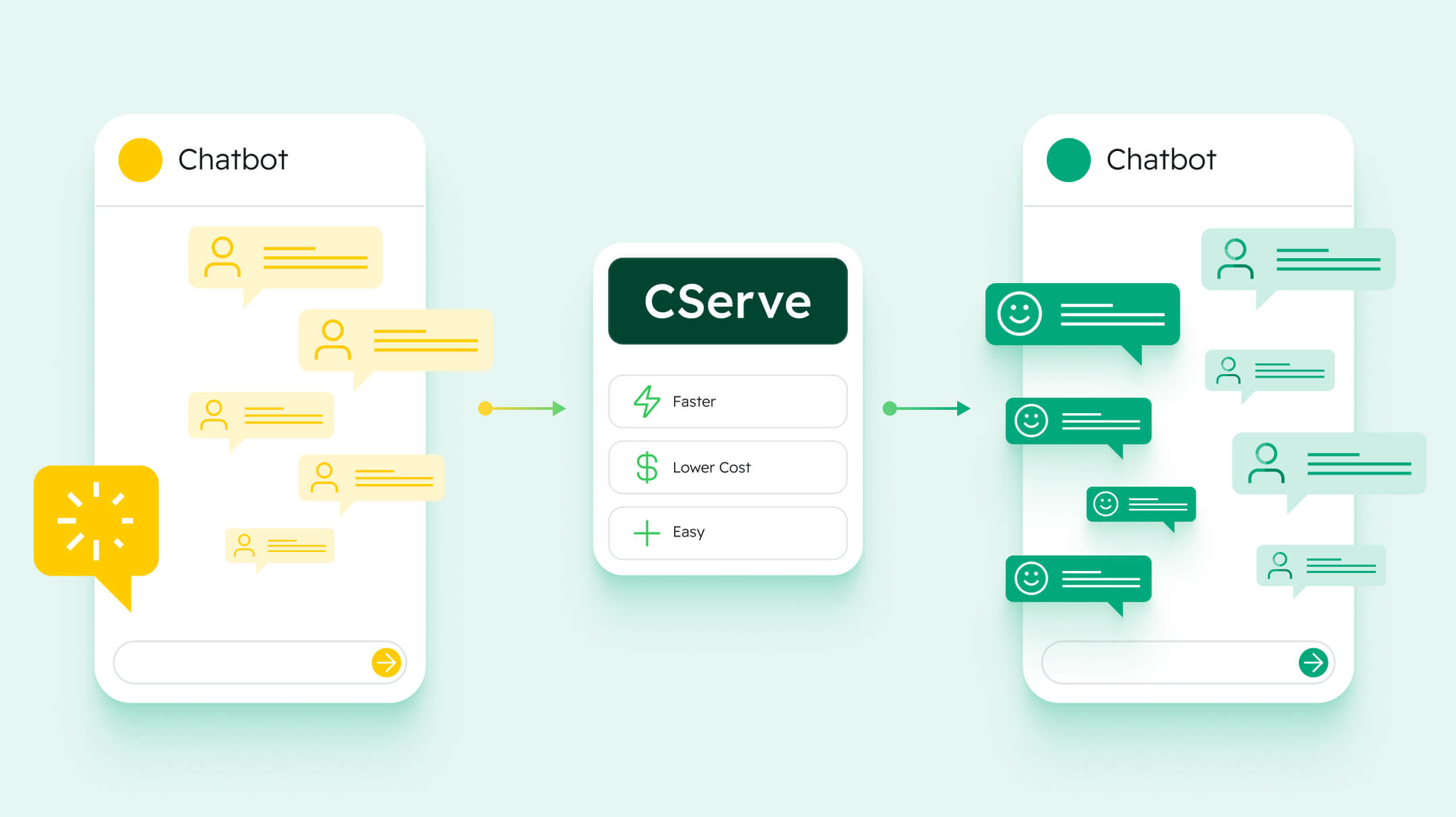
Our Products

Our Open Source Solutions
Explore the dynamic duo of optimization with Hidet, our open-source compiler, and DeepView, the open-source profiler. Together, they empower AI engineers to unlock performance, gain invaluable insights, and transform the way they develop their models.
Hidet
Complier

Hidet is an open-source deep learning compiler, written in Python. It supports end-to-end compilation of DNN models from PyTorch and ONNX to efficient cuda kernels. A series of graph-level and operator-level optimizations are applied to optimize the performance.
Learn MoreDeepView
Profiler

CentML DeepView provides an integrated experience which allows ML practitioners to visually identify model bottlenecks, perform rapid iterative profiling, understand energy consumption and environmental impacts of training jobs, and predict deployment time and cost to cloud hardware.
Learn MoreTestimonials

Misha Bilenko
VP of AI @ Microsoft Azure

David Patterson
Distinguished Engineer @ Google

Aleks Smechov
CEO & Co-founder @ Wordcab

Garth Gibson
Former CEO & President @ Vector Institute
David Patterson
Distinguished Engineer @ Google

Ruslan Salakhutdinov
CMU Professor

Graham Taylor
Vector Institute for Artificial Intelligence

Vinod Grover
Senior Distinguished Engineer and Director of CUDA and Compiler Software at NVIDIA

Tamara Steffens
TR Ventures Managing Director


Media About Us




