From Constraint to Competitive Edge: Exploring EquoAI’s Tech Leap with CentML
Learn how EquoAI economically builds LLMs and seamlessly deploys multiple LLMs in a single click with CentML's CServe.

In this case study, we take a closer look at how EquoAI reduced its LLM deployment costs, improved deployment efficiency, and drove significant competitive advantage with CentML GPU optimization.
Meet EquoAI
Founded in 2023, EquoAI evolved from researching Generative AI adoption barriers to providing GenAI solutions. Now, the company offers white-label RAG and data services using open-source LLMs, addressing enterprise concerns like data privacy, high costs, and expertise gaps. EquoAI’s solutions are deployable on-premise or within specific geographic boundaries, tailored to client needs.
Objectives & Challenges
From running multiple LLMs to building within the Canadian legal ecosystem, the CentML team helped EquoAI manage several critical challenges:
- Managing multiple models: A legal document summarization pipeline was built using Mixtral, Llama3-70B, Pegasus, and other popular fine-tuned or quantized LLMs.
- Adhering to legal requirements: EquoAI’s data and resulting application was deployed within Canada due to legal requirements.
- High costs and limited GPU availability: The cost for running LLMs was high and availability of large GPUs was limited.
Solutions: LLM Optimization
With CentML, EquoAI was able to build LLMs and also seamlessly deploy multiple popular LLMs in a single click:
- Single-click deployment: CentML helps EquoAI run Mixtral, Llama3-70B, and Pegasus on readily available and inexpensive A10 instances with CServe’s click-to-launch deployment process.
- LLM evaluation: The CentML platform (along with CServe) allows EquoAI to rapidly compare LLMs based on quality, speed, and cost of deployment. This allows for a smooth and scalable path from prototype to deployment at scale.
- Build and serve: EquoAI uses the CentML platform for building and serving LLMs within Canada.

Results: Preserving Critical Resources
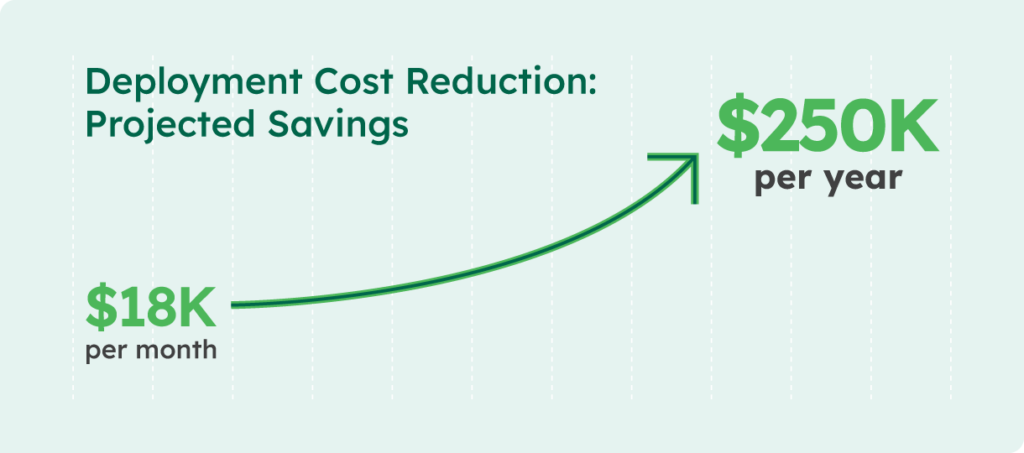
Working with CServe, EquoAI significantly reduced the resources required for successful deployment. This will lead to a potential savings of nearly $250K over the year.
- Reduced deployment costs: By migrating from Azure ML to CentML, EquoAI reduced deployment costs by 2.8x (from $3.84 to $1.3 per GPU) while improving GPU availability. This results in a projected savings of over $18K a month, and nearly $250K a year.
- Faster development time: CentML’s pre-built LLM service cut development time from days to minutes. This simplifies LLM deployment and provides significant go-to-market advantage.
- Optimized GPU consumption: CServe optimizations halved GPU consumption for Mixtral-8x7B from 8 to 4 GPUs, resulting in an additional 2x cost reduction.
Benefits: Greater Capacity for Growth
By freeing resources from cost-heavy AI implementation, EquoAI’s transition to CentML has already helped strengthen its go-to-market strategies:
- Competitive edge: EquoAI can now offer more cost-effective and performant AI solutions to clients, enhancing its market position.
- Expanded service portfolio: EquoAI can now deploy a wider range of LLMs with predictable costs and timelines. This increases the flexibility of its client offerings.

Looking to optimize your LLMs and ML workflows? Contact us at sales@centml.ai or book a demo.
Share this

