Introducing CServe: Reduce LLM deployment cost by more than 50%
Run LLMs on budget-friendly GPUs and still get top-notch results

tl;dr: We’re excited to introduce CServe—an easy-to-deploy, highly efficient, and low-cost serving framework for LLMs to help you cut your operational costs in half while optimizing for both server-side throughput and client-side latency constraints.
Generative AI is BIG. We’ve witnessed its power with ChatGPT. But if AI is the future that can benefit us all, it’s unlikely that ChatGPT is the only way we’ll interact with it. Soon, we’ll be using AI for new use cases never before imagined, and in forms other than online chatbots.
Fortunately, there are open-source foundational models like Llama-2, Mistral, Falcon, OPT, GPT-NeoX, and others to help us get there. The problem is…deploying these large language models (LLMs) on your hardware is too complex. Many technologies require expensive and specialized hardware, most of the optimization techniques don’t work well together, and are not readily available.
That’s why today we’re excited to introduce CServe!
CServe is a model deployment and serving framework designed to make your LLM deployment cheaper, easier, and faster.
In this post, we’ll show you:
- How to reduce deployment costs by 58% while maximizing server-side throughput
- How to reduce deployment costs by 43% while maintaining client-side latency constraints
NOTE:We’ll focus on on-premise deployment. Stay tuned for hosted inference in the next post.
What’s the problem with vLLM, TGI, and TensorRT-LLM?
The short answer is—there is no problem (aha!). But, there is a problem if they’re not used under the exact setup that these systems were designed for.
We’ve spent a lot of time studying these systems and talking to users to optimize their LLM deployment. In most use cases, people not only care about the raw latency of a single request; they also care about model quality, security and privacy, resource requirements, ease of use, and more importantly: cost.
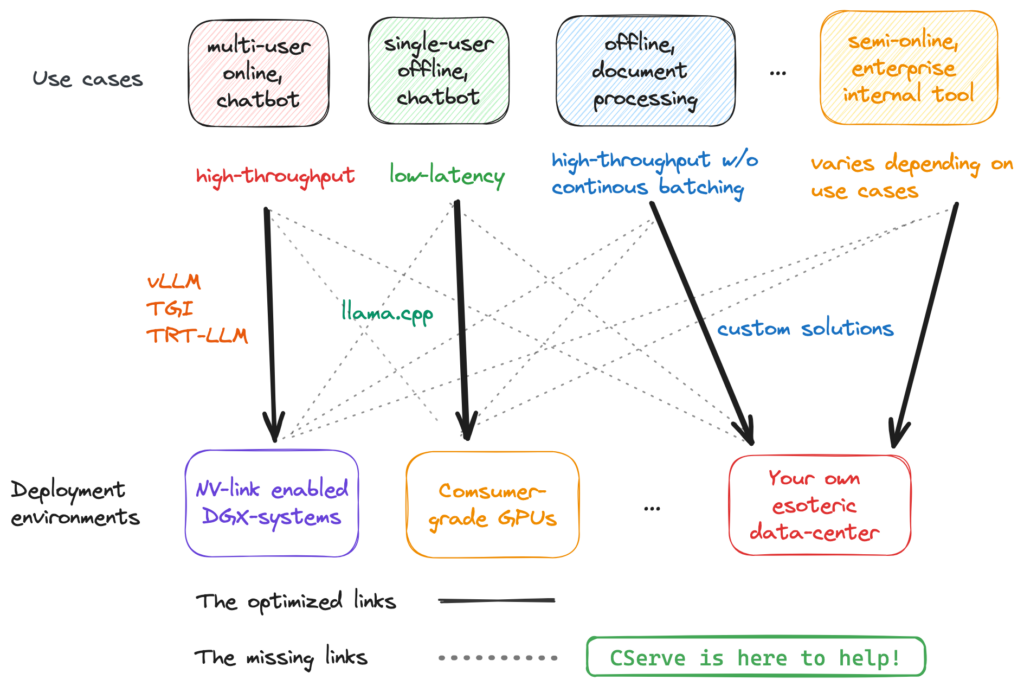
Our verdict: There’s no single perfect recipe for optimizing the technology for your solution—to make it cheaper and more accessible, especially if you’re being creative with your AI project.
The solution: CServe
Today, we’re launching CServe to help you optimize your LLM deployment for all kinds of scenarios with all state-of-the-art LLM inference optimizations:
- Most open-sourced LLMs (Llama, Falcon, Mistral, etc)
- Continuous batching + token streaming
- Paged attention
- Tensor/pipeline parallel
- Quantization
- And much more!
It’s still a work in progress, but we wanted to share it with you early (and before the holidays 😉) to save you the cost of paying for suboptimal solutions and getting locked into suboptimal technology.
Let’s take a look at how CServe works.
NOTE: We’ve tested all queries with 512 prompt sizes and 256 generation sizes, but we support the maximum token sizes specified by the model architecture. For the following examples, we calculated the deployment cost using on-demand pricing for the corresponding cloud GPU instances. However, the story applies to any type of cost calculation concerning your on-premise environment.
1. How to reduce deployment costs by 58% while maximizing server-side throughput
You want to process inputs with maximum throughput, but the most effective solution doesn’t mean the most expensive solution (like NVIDIA DGX systems). Sure, if you care only about throughput, it might work. But the performance of that infrastructure may not be worth the price.
With CServe, you don’t need to buy expensive GPUs.
You can run your LLMs on cheap GPUs with the same result.
Let’s say you use your LLM for offline document processing (i.e., text summarization or code analysis). The key metric for an ideal inference deployment is performance per dollar: process the most documents for a given computational budget. CServe can help you identify the best set of hardware choices (e.g., the type of GPUs, the interconnects, the number of GPUs, etc.) and optimization strategies (e.g., with or without paged attention, pipeline parallel or tensor parallel, speculative decoding, etc.) that will give you the best cost.
In this example of CodeLlama-34B + CServe, choosing multiple instances of L4 GPUs can reduce your cost by 58% when compared to the standard deployment of 4xA10 instances:

The graph above shows both the throughput (in light green) and the cost (in dark green) for a single replica of the CodeLLama-34B inference engine using CServe. While using 4xA100 gives the best throughput, the cost of deploying 4xA100 is significantly higher (almost 4x than 4xL4 GPUs), making it up to 29% less cost-effective than L4 GPUs. If you don’t have access to A100 GPUs, the difference between the most cost-effective solutions for each GPU instance can be as much as 58%.
2. How to reduce deployment costs by 43% while maintaining client-side latency constraints
You have user experience requirements. Each text completion query needs to be completed in a certain amount of time. So you decide that you can’t have a hundred users on the same server just because that helps with your server throughput. You have a cap, and you have to ensure a great individual user experience.
With CServe, you can deploy with the fewest number of GPUs that meet your latency constraints and get the best performance per dollar. In other words…
You don’t have to sacrifice user experience—you can get it at a much lower cost.
When you deploy an AI chatbot, you expect your users not to get bogged down reading the text. So you choose a minimum text generation latency of 10 tokens per second—slightly faster than the average reader’s reading speed. This constraint changes the best set of optimizations and hardware alternatives.
For example, if the request rate is low and the memory capacity isn’t an issue, you no longer need paged attention to manage GPU memory, since it introduces only latency overhead. Also, the ideal size of tensor parallel workers changes depending on your constraints, and you don’t want to overprovision tensor parallel workers to introduce unnecessary communication costs.
In this example with Llama2-70B, CServe will generate a set of optimization strategies and deployment plans that satisfy your constraint, while still achieving the lowest cost of deployment and optimized inference engines. If you have A100 GPUs available, the right number of parallel workers (4 instead of 8) can reduce the cost by 30%. If you don’t have A100 GPUs, the right type of GPU (L4 instead of A10) can reduce the cost by 43%.

Similar to the previous graph, the graph above shows the throughput (in light green) and the cost (in dark green) for a single replica of the Llama2-70B inference engine using CServe. But this time, we ensure a maximum speed per request of at least 10 tokens per second. This effectively reduces the maximum number of current requests allowed for each engine, hence the memory pressure. The requirement changes create a ripple effect of changes in optimization strategies such as paged attention and request scheduling. The result is a lower cost (30%) with fewer A100 GPUs, or a lower cost (43%) with a better hardware choice.
What’s next?
If you’re working on an AI project and would like to give CServe a try, please contact me at xin@centml.ai or @xinli-centml. We’re planning to make CServe publicly available in early 2024 and would love to hear your feedback and how we can tailor it to your specific needs.
Thank you for inspiring us to keep moving forward. We’re excited to empower you to train and deploy the best and most powerful models.
Here’s to the future of accessible AI! 🚀

Share this

