Make your ML models run faster with Hidet
Optimize your PyTorch and ONNX models and streamline the deep learning process

Hidet is an advanced deep learning compiler developed by CentML. It improves AI model optimization and is more efficient than traditional tools, especially for PyTorch and ONNX models. We’re excited to demonstrate the capabilities of Hidet and how it seamlessly integrates into the deep learning workflow! 🔥
In this post, we’ll cover:
- What Hidet is and who it is for
- The benefits of using Hidet
- Step-by-step instructions on how to use Hidet
Let’s dive in!
What is Hidet?
Hidet is an open-source deep learning compiler that offers end-to-end optimization for deep learning models defined in PyTorch, ONNX, or its own high-level APIs.
If you need to optimize a specific operator, Hidet also offers a domain-specific language embedded in Python. With this language, you can develop optimized kernels and use them seamlessly in Python.
Who is Hidet for?
We built Hidet for data scientists and ML engineers like you who want to take their deep learning performance to the next level.
Whether you’re working on small-scale projects or large-scale model deployments, Hidet can help you optimize performance at both the operator and graph levels. Our domain-specific language (DSL) allows for the efficient development of optimized kernels, which combined with automatic graph optimizations result in highly optimized end-to-end performance.
What are the benefits of Hidet?
There are two ways to run a deep learning model:
- Deep learning frameworks like PyTorch use eager mode, where operators are executed eagerly and pre-built kernels from vendor libraries like cuBLAS/cuDNN or custom implementations are used.
- Deep learning compilers like Hidet and TVM first represent the computation as a graph, with operators as nodes and tensors as edges. Hidet optimizes the graph and generates kernels specific to the target hardware and model input sizes.
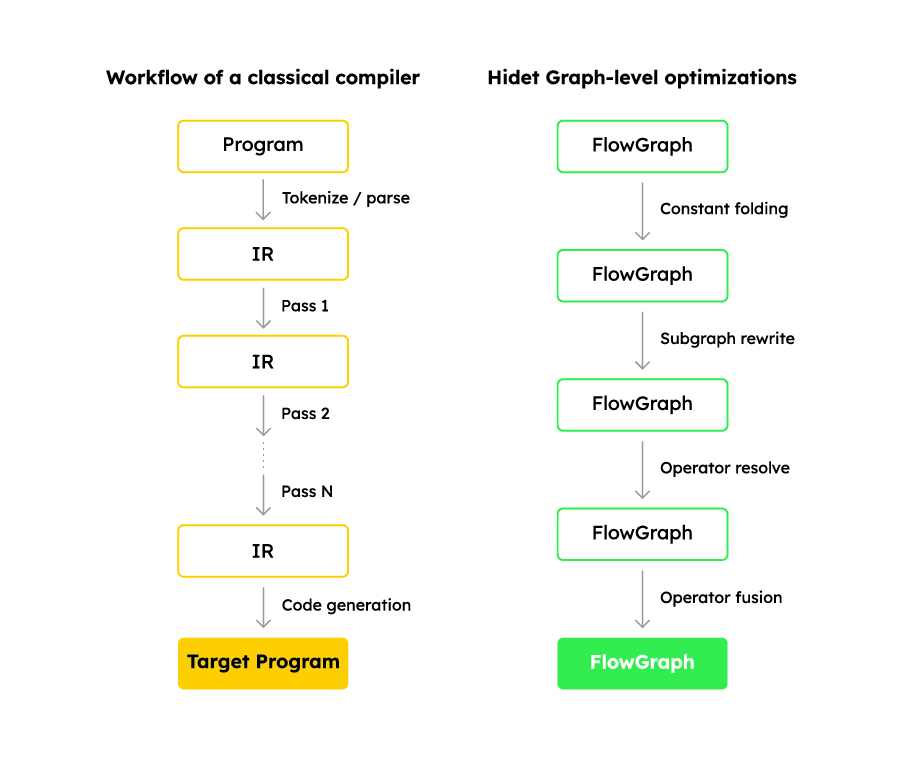
To illustrate the benefits of using Hidet, we have compared the workflows of classical compilers and Hidet.
Benefit 1. Organize optimizations systematically
A typical compiler translates a program from one language to another. During the translation process, there are multiple passes of transformations to optimize the program.
Hidet converts the model into a computational graph representation, FlowGraph. In FlowGraph, you can abstract optimizations such as sub-graph rewrite, operator fusion, and quantization into passes and let the compiler apply these optimizations systematically and automatically.
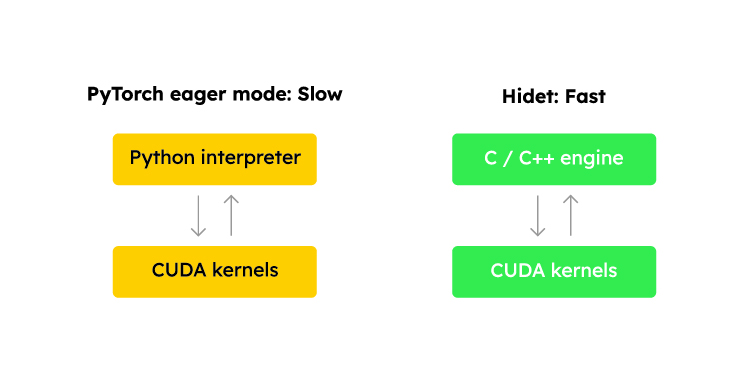
Benefit 2. Less runtime overhead
When running a PyTorch model, the Python interpreter executes the PyTorch code written in Python. PyTorch, in turn, launches a CUDA kernel when an operator is executed.
Although the CPU-GPU is asynchronous (i.e., the CPU code resumes execution once it has finished launching the kernel without waiting for the kernel to complete), running a model with small CUDA kernels (i.e., those that complete quickly) can result in noticeable Python overhead.
Hidet generates C code to launch these CUDA kernels, reducing the overhead imposed by the Python-based framework.
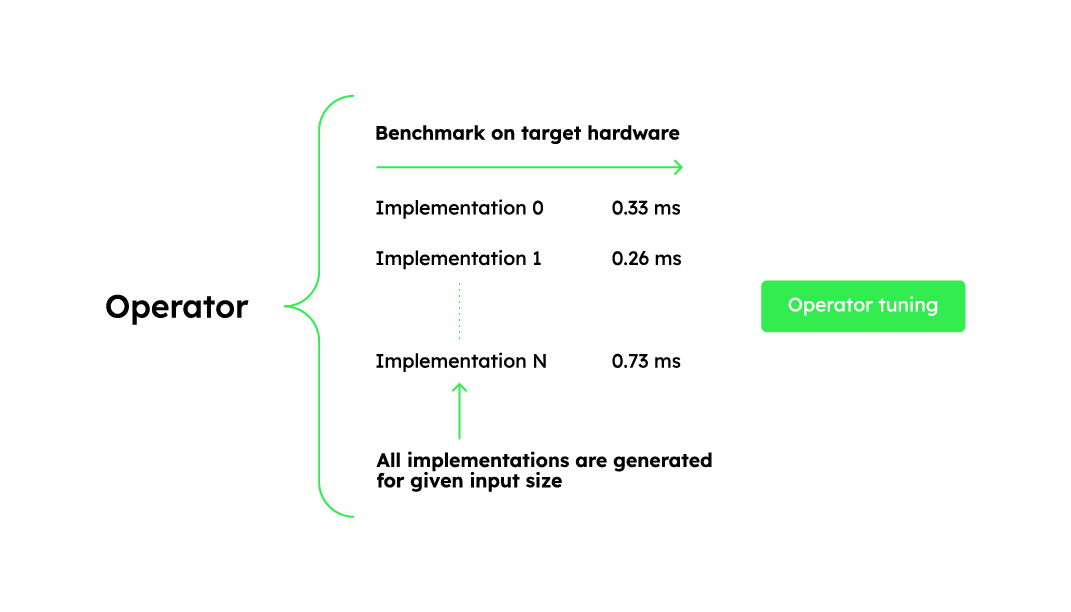
Benefit 3. Operator tuning for target workload and hardware
For the same operator, the best kernel implementation varies depending on the input size and hardware.
For example, when performing matrix multiplication, a large matrix multiplication (e.g., 4096x4096x4096) benefits from a large tile size (e.g., 256×128) to divide the workload into parallelizable subtasks. However, as the input size decreases (e.g., 512x512x512), this tile size becomes inefficient. To get the best performance for different input sizes, you need to choose different hyperparameters, such as tile sizes.
Vendor libraries such as cuBLAS and cuDNN provide a wide range of kernels targeting different input sizes and hardware configurations. However, they may not cover all use cases and hardware configurations. To address this, deep learning compilers use operator tuning to generate optimized kernels for specific input sizes and hardware.
Hidet generates multiple kernels for each input size and hardware, compares their performance, and selects the best one. This reduces the binary size of the compiled model and improves performance.
How to use Hidet?
Under the hood, Hidet translates Python code into its intermediate language, applies a series of optimizations, and generates optimized CUDA code. The CUDA code is then compiled using NVIDIA’s nvcc compiler. The compiled binary is loaded into the Python interpreter and used by users.
Compared to other alternatives such as OpenAI Triton, with Hidet Script users can manage more fine-grained resources on accelerators (such as shared memory and registers in NVIDIA GPUs) and implement optimizations that haven’t yet been added to the OpenAI Triton compiler.
Using Hidet is super easy. Just install it using pip:
pip install hidet
Once installed, try optimizing your deep learning models or simplifying the process of writing kernels.
Here are some examples to play with.
Example 1. Optimize a ResNet18 model
import hidet
import torch
# load resnet18 from torch hub
x = torch.randn(1, 3, 224, 224).cuda()
model = torch.hub.load('pytorch/vision:v0.9.0', 'resnet18', pretrained=True, verbose=False).cuda().eval()
# set the search space for operator tuning
hidet.torch.dynamo_config.search_space(2)
# optimize the model with 'hidet' backend
model = torch.compile(model, backend='hidet')
# run the optimized model
y = model(x)Example 2. Build a naive matrix multiplication kernel
import torch
def build_matmul_kernel():
import hidet
from hidet.lang import attrs
from hidet.lang.types import f32, i32, tensor_pointer
from hidet.lang.cuda import blockIdx, threadIdx, blockDim
with hidet.script_module() as script_module:
@hidet.script
def matmul(
m_size: i32, n_size: i32, k_size: i32,
a_ptr: ~f32, b_ptr: ~f32, c_ptr: ~f32 # ~f32 means a pointer to f32
):
# specify the function kind as 'cuda_kernel'
attrs.func_kind = 'cuda_kernel'
# specify the grid dimension and block dimension
attrs.cuda.grid_dim = (m_size + 15) // 16, (n_size + 15) // 16
attrs.cuda.block_dim = 16, 16
a = tensor_pointer(f32, shape=[m_size, k_size], init=a_ptr)
b = tensor_pointer(f32, shape=[k_size, n_size], init=b_ptr)
c = tensor_pointer(f32, shape=[m_size, n_size], init=c_ptr)
# the coordinate of the c matrix that this thread is responsible for
i = blockIdx.x * blockDim.x + threadIdx.x
j = blockIdx.y * blockDim.y + threadIdx.y
if i < m_size and j < n_size:
acc = f32(0.0)
for k in range(k_size):
acc += a[i, k] * b[k, j]
c[i, j] = acc
return script_module.build()
matmul_kernel = build_matmul_kernel()
def matmul(a: torch.Tensor, b: torch.Tensor) -> torch.Tensor:
m_size = a.size(0)
n_size = b.size(1)
k_size = a.size(1)
c = torch.empty(m_size, n_size, dtype=torch.float32, device='cuda')
matmul_kernel(m_size, n_size, k_size, a, b, c)
return c
# compare the result with torch.matmul
a = torch.randn(100, 100, dtype=torch.float32, device='cuda')
b = torch.randn(100, 100, dtype=torch.float32, device='cuda')
c = matmul(a, b)
torch.testing.assert_close(c, a @ b, atol=1e-5, rtol=1e-5)For more examples, read Hidet docs or check out Hidet on GitHub.
What’s next?
As we continue to refine Hidet, we’d love to see how you use it in your projects. Please send your comments, feedback, and ideas to sales@centml.ai or connect with us on LinkedIn.
We’re on track to release more features for Hidet by the end of the year, and we’d love to incorporate your input to make it even more powerful.
Join us in optimizing AI to make it more efficient and accessible for everyone! 🌟
Resources
Hidet documentation
Hidet on GitHub
Hidet research paper

Share this

