Maximizing LLM training and inference efficiency using CentML on OCI
Unlocking the potential of cost-effective NVIDIA GPUs for advanced ML workloads

In partnership with CentML, Oracle has developed innovative solutions to meet the growing demand for high-performance NVIDIA GPUs for machine learning (ML) model training and inference. Utilizing CentML’s state-of-the-art ML optimization software and Oracle Cloud Infrastructure (OCI), the collaboration has achieved significant performance improvements for both training and inference tasks, specifically with the LLaMa-V2 and Falcon-40B models.
Key findings indicate that OCI outperforms other public cloud service providers because of reduced virtualization overhead, and CentML’s optimizations significantly enhance performance metrics across the board. The breakthroughs have demonstrated that it is possible to achieve compelling performance even on more readily available NVIDIA Tensor Core GPUs like the NVIDIA A10 Tensor Core GPU with 24GB of memory, offering cost-effective alternatives to top-of-the-line GPUs, such as the NVIDIA A100 and H100 Tensor Core GPUs.
Background
The emergence of ChatGPT and LLaMa series large language models (LLMs) has demonstrated the potential of generative AI, serving as the catalyst for the ongoing AI revolution. Oracle has collaborated with customers to help them navigate their artificial intelligence (AI) and ML journey and achieve their objectives. The surge in AI has resulted in an insatiable demand for high-end GPUs, like the NVIDIA A100 and H100 GPUs, to support LLM training and inference.
Given this surge, AI/ML developers need to plan for a number of factors outside of just compute, including time-to-market constraints. As a result, Oracle, in partnership with CentML, has embarked on a mission to offer customers a greater variety of NVIDIA GPUs for AI training and inference. From the H100 GPU to the A10 GPU, developers can pick and choose the NVIDIA-powered instance that is best in -line with their own go-to-market strategy to position themselves for success.
The combination of CentML’s unprecedented ML-model performance optimization software with OCI’s Gen-2 cloud has achieved remarkable performance results for NVIDIA A10 24GB GPU- optimized LLM training and inference.
Oracle and CentML’s teams have collaborated on the following use cases:
- Accelerate LLaMA-V2 (7B) serving
- Fine-tune training Falcon-40B on OCI instances powered by NVIDIA A10 GPUs
Accelerate LLaMA-V2 (7B) serving
Using CentML’s deep learning compiler, we accelerated LLaMA-v2 only days after its release, demonstrating compelling performance improvements.
In the LLama 2 inference serving performance test, measuring latency and throughput on OCI, we used the following benchmark parameters:
- FP16
- Prompt Length: Approximately 10 tokens
- Generated Sequence Length: 255 tokens
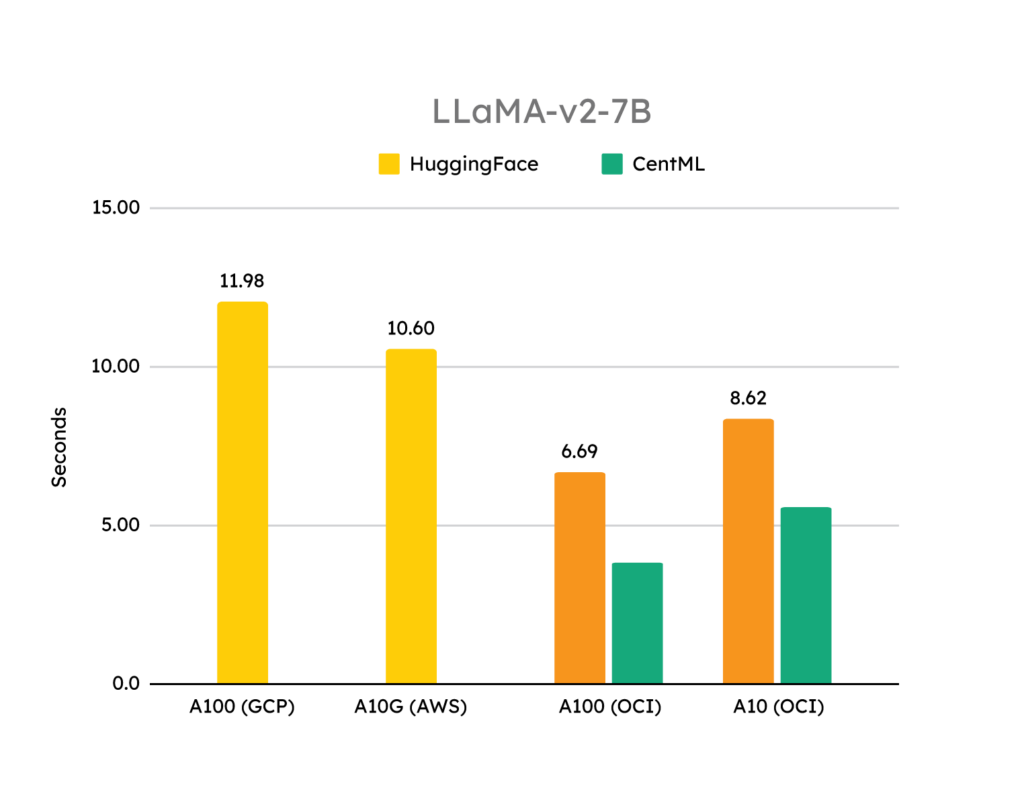
From these tests, we gather the following takeaways:
- OCI is faster than other public cloud services out-of-the-box, because it eliminates virtualization overhead.
- CentML optimizations can improve LLaMA-v2 inference serving performance by 48% on OCI over its competitor and further optimize performance on OCI by 36%.
- CentML optimizations on NVIDIA A10 GPUs achieved 1.2 times better performance than NVIDIA A100 GPU performance without CentML optimizations.
Equally as exciting as the performance results we achieved for inference serving is the performance we attained for LLM fine-tune training on the NVIDIA A10 24 GB GPU.
Fine-tuning Falcon-40B on OCI GU1 instance powered by NVIDIA A10 GPUs
As mentioned, access to top-of-the-line NVIDIA GPUs, like the A100 and H100, is even more acutely felt for fine-tuning workloads. The reason that everyone is after top-of-the-line GPUs is that you can fit the model into the memory of the chip. But what if the size of the model exceeds the available memory of the GPU? Can you run the fine-tuning workload on GPUs that are more readily available?
Applying CentML’s advanced techniques for data and model parallelism, we successfully ran a fine-tuning training workload of the Falcon-40B model on NVIDIA A10 GPUs. We established the following test case criteria for evaluation:
Benchmark metadata
- Model: Falcon-40B
- 4 GPUs
- Sequence length generated: 2,048
OCI GM 4 instance (powered by NVIDIA A100 GPUs) baseline test
- 4 x NVIDIA A100 40-GB GPUs with NVIDIA NVLink technology
- Data- parallel fine-tuning
- Per GPU throughput: 1,324 samples/hour
OCI GU1 instance (powered by NVIDIA A10 GPUs) baseline test with Hugging Face native model parallelism
- 4 x NVIDIA A100 40-GB GPUs with NVIDIA NVLink technology
- Popular existing frameworks like Deepspeed and Megatron require users to modify the model implementation of Falcon-40B and don’t support important functionality like low-bit precision and LoRA.
- Hugging Face two-way model parallelism
- Per GPU throughput: 191 samples/hour, which is almost seven times slower than the NVIDIA A100 baseline
OCI GU1 instance (powered by NVIDIA A10 GPUs) baseline with CentML training framework
- 4 x NVIDIA A10 -24GB GPUs connected by PCIe
- No modification to the Falcon-40B model
- Per GPU throughput using two-way pipeline parallelism: 296 samples/hour
Results
In the following table, understand the following acronyms:
- DP: Data- parallel fine-tuning using HuggingFace Trainer
- MP: Model- parallel fine-tuning using Huggingface Trainer
- MP+TP: Model- and data- parallel fine-tuning using open-source libraries
- CentML: A mixture of parallelization and optimization strategies devised by CentML
| A100 GPU (DP) | A10 GPU (MP) | A10 GPU (MP+TP) | A10 GPU (CentML) |
| 1,324 samples/hour | 109 samples/hour | 191 samples/hour | 296 samples/hour |
| $12.20/hr | $8/hr | $8/hr | $8/hr |
| 108.50 Samples/dollar | 13.61 Samples/dollar | 23.90 Samples/dollar | 37.04 Samples/dollar |
We have the following key takeaways from our exceptional results:
- CentML training framework doesn’t require model changes and automatically scales with model size.
- Using CentML on OCI, you can perform model fine-tuning that scales from 7B to 60B parameters.
- Consider running LLM’s like Falcon-40B at scale on NVIDIA A10 GPUs on OCI with CentML services.
Through the application of two-way pipeline parallelism, the NVIDIA A10 GPU showcases a throughput of 296 samples/hour. While slower than the NVIDIA A100 GPU baseline, this result reveals the untapped potential of the NVIDIA A10 GPU infrastructure.
When combined with CentML’s optimization, the NVIDIA A10 GPU’s performance offers a remarkable 37.04 samples/dollar ratio. This advantage can be a game-changer for organizations looking to maximize performance and flexibility while facing the need to scale their models immediately.
Conclusion
In an industry constrained by the limited availability of high-performance GPUs, Oracle and CentML provide a groundbreaking solution to your performance, cost, and scalability challenges. Our collaboration unlocks the untapped potential of more readily available GPUs, such as the NVIDIA A10 GPU, offering you optimized performance at a remarkable cost-benefit ratio.
Act now to use the unmatched capabilities of CentML’s optimization techniques and Oracle Cloud Infrastructure’s robust NVIDIA GPU-powered cloud infrastructure.
Contact us today to discover how you can achieve your unique training and inference goals while maximizing performance, cost efficiency, and flexibility.
Authors
Sanjay Basu PhD, Senior Director – Gen AI/GPU Cloud Engineering
Ron Caputo, Oracle AI Cloud Sales Director
Akbar Nurlybaev, Co-founder and COO, CentML
The authors want to thank Shang Wang, Xin Li, and Zhanda Zhu for their contributions.
Share this

