Optimize or Overpay? Navigating Cloud GPU Choices for ML Models
Choosing the right GPU for your machine learning workload can be a costly guessing game. Enter DeepView, a tool that takes the guesswork out of GPU selection by accurately predicting your model's performance across various cloud GPUs.

DeepView accurately predicts ML model performance across various cloud GPUs, helping you choose the most cost-effective option. It reveals whether upgrading to pricier GPUs like the H100 is truly beneficial for your specific workload, potentially saving time and resources. The tool also helps identify and resolve performance bottlenecks, ensuring optimal GPU utilization.
Introduction
Cloud computing offers a diverse array of GPUs, from cost-effective older models like T4 and V100 to cutting-edge units such as A100, L4, and H100. While the latest NVIDIA H100 GPUs boast remarkable capabilities, including TensorCores and support for low-precision computations, they come at a significant cost—approximately twice that of the previous generation A100 GPUs—and are challenging to access due to limited availability.
The efficiency of using the latest GPUs heavily depends on your ML model’s specific requirements. In many cases, slightly older GPUs can deliver comparable performance at a significantly lower cost. What if you could know in advance the most cost-efficient GPU for your specific ML workload? This foresight could save you time and effort, preventing situations where you gain access to an H100 only to discover it runs just as fast as your current GPU.
DeepView: Accurately predicting model performance
DeepView can tell you in advance how much faster (or slower) your training will run on a large range of available GPUs in clusters and the cloud.
This powerful tool provides you with the insights needed to make informed decisions about which GPU to use for your ML model, saving you both time and resources.
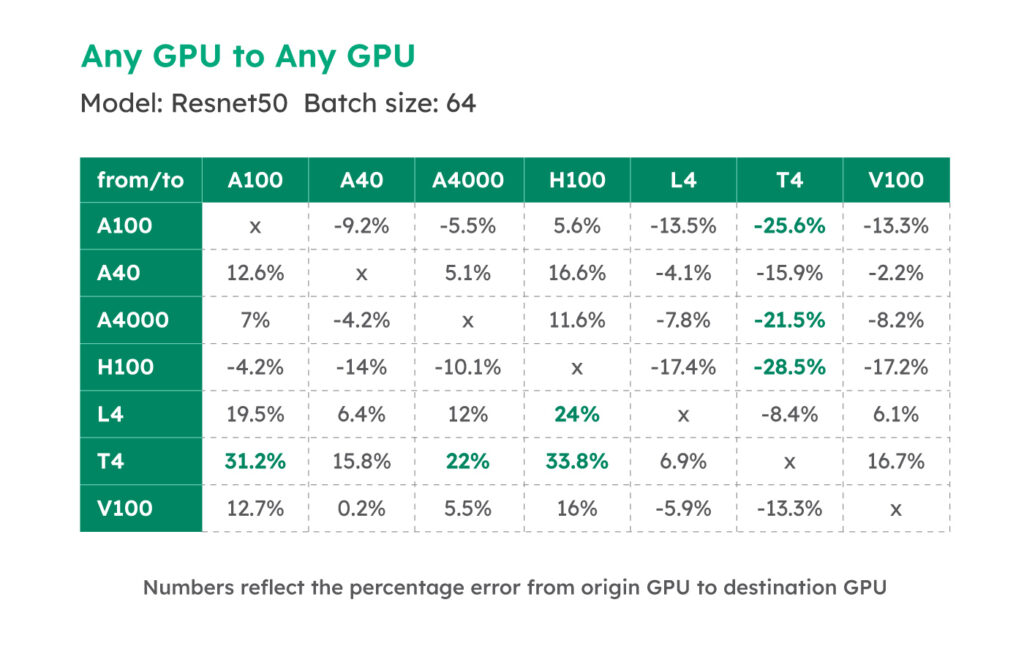
DeepView.Predict provides fine-grained performance predictions by mapping each operation of your ML model to the target GPU. This approach ensures much more accurate predictions compared to heuristic alternatives, which can often result in large errors (>40%). Having precise predictions tailored to your exact model is far more valuable than relying on rough performance estimates of popular models found online, which frequently differ significantly from your real-world experience.
Case Study: Should I switch from L4 to H100?
Suppose you have abundant access to L4 GPUs and wish to test model performance on the H100. The predictions are summarized in the table below:
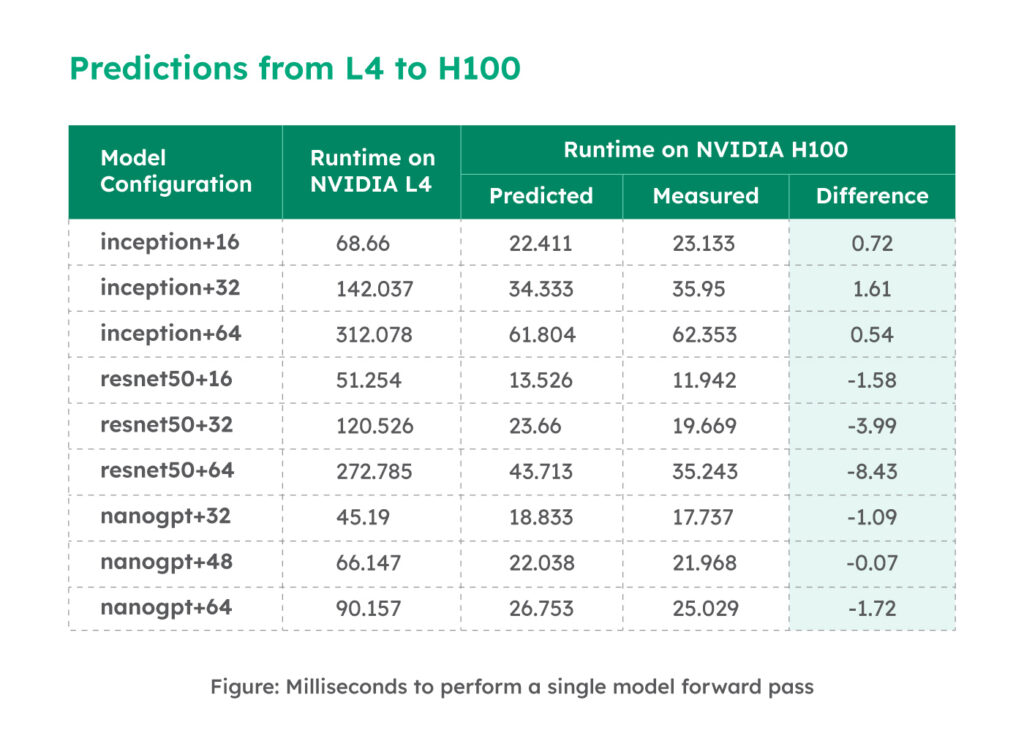
When you don’t see significant speedups by upgrading to the H100, you have two options:
- continue training your model on a less powerful GPU, or
- modify your training setup to take advantage of the H100’s larger compute capacity.
In the latter case, the lack of utilization is potentially due to the size and complexity of your model or compute bottlenecks elsewhere. For instance, your GPU might be idling most of the time, waiting for other CPU operations such as data loading to complete.
DeepView: The Deep Learning Visual Profiler
DeepView is a visual profiler for deep learning workloads and can help you identify training bottlenecks to get the optimal performance for your training setup. DeepView also got a refreshed UI, outlining performance information in a more intuitive layout:
Using DeepView, you can easily identify these bottlenecks, achieving better performance locally and greater speedup on more powerful devices.
Summary
Selecting the right GPU for your ML workloads is challenging, especially considering the costs and limited availability of GPUs like the NVIDIA H100. Predicting performance on these GPUs is essential. DeepView can inform you about your model’s performance on the H100 and a wide range of other GPUs directly on your computer.
Underperformance often results from a lack of optimization. DeepView, an intuitive profiler, helps identify why your models don’t scale. By providing precise predictions and pinpointing bottlenecks, DeepView ensures optimal choices for your training setup.
Don’t leave your GPU selection to guesswork. Try out DeepView today and start optimizing your machine-learning workflows for better performance and cost efficiency.
Explore DeepView at https://docs.centml.ai
Share this

